* 1. [Q 业务整体流程](#Q)
* 2. [Q DDD架构设计](#QDDD)
* 3. [Q 库表设计?为什么?](#Q-1)
* 4. [Q 哪些需要分库,哪些需要分表?](#Q-1)
* 5. [Q 项目中抽奖如何实现O(1)复杂度的?](#QO1)
* 6. [Q 讲一讲你项目中如何使用责任链模式前置处理抽奖的?什么场景使用它,什么场景使用组合模式?](#Q-1)
* 7. [Q 讲一讲你的项目中如何使用规则树处理后置抽奖的?如何通过模板模式串联整个抽奖过程的?](#Q-1)
* 8. [Q 抽奖减库存如何支持高并发量的?不超卖规则如何实现的?](#Q-1)
* 9. [Q 如何解决重复下活动订单的问题?](#Q-1)
* 10. [Q 写入中奖记录的时候,需要存库和发MQ,如何模拟事务实现?](#QMQ)
* 11. [Q 生产者可能多次发送同一个MQ,如何保证产品不会超发的?](#QMQ-1)1. Q 业务整体流程
A:

首先系统开启以后应该先执行
-
预热装配,预热装配即将活动数据和抽奖策略,奖品数据装到redis缓存中,通过activityId 查找sku,sku是活动id和活动次数的结合,通过sku可以得到活动信息和活动存量,活动次数,预热放到redis缓存。然后一个活动对应一个strategyId(抽奖策略),绑定可以预热活动策略。预热策略逻辑即首先根据策略查出奖品,并缓存。然后根据奖品概率生成概率范围数组(map),缓存。然后再查出所有的预热权重策略进行拼接key的缓存预热装配。
-
执行抽奖,传入参数用户id和活动id。首先进行参数校验,然后参与活动创建抽奖订单。
2.1 创建订单:首先看有没有非使用过的订单,有的话直接返回。否则创建一个活动订单,因为每个用户都每天有额度限制,所以会用单独的表记录一个用户的日剩余次数表(没有创建过则创建,有了的话则日剩余-1)。创建出来抽奖订单userRaffleOrder状态为未使用,入库。
2.2 执行抽奖:执行抽奖是走的策略服务,传入的参数是userId和strategyId。抽奖流程首先执行责任链抽奖计算 BlackList -> RuleWeight -> Default。其中Default是默认的抽奖策略,即从0 - rateRange(根据前面的链存在redis里面获取)中随机数从装配的Map中直接获取。责任链封装出来awardId和链的阶段返回。然后进入规则树,在StuckStock节点中先对缓存库存扣减,再发异步定时任务到延时队列,用定时任务轮询得到任务到mysql操作,再最终然后得到最后的奖品id(规则树包括rule_lock和rule_awardluck节点),通过mysql根据strategyId和awardId包装成最终奖品。
2.3 封装用户中奖记录:这里要mysql写入和MQ发送抽奖记录(为什么需要MQ发送需求?),但是这两个操作不能同一事务,所以需要用一个task做任务补偿。

2. Q DDD架构设计
A: DDD分为接口层(big-market-api),应用层(big-market-app),领域层(big-market-domain),基础层(big-market-infrastructure)
该项目中还有专门的big-market-trigger层和big-market-types层,前者负责定时任务,消息队列消费者监听等,后者负责管理类型的
领域层主要是实现对实体的属性和方法的封装,通过这种方式封装了核心业务。项目中有活动、奖品、策略、任务四个领域。每个领域一般分为这几个包:
3. Q 库表设计?为什么?
A:首先是策略相关的表:
(1)strategy表,除了主键,还需要注意的是rule_model。因为可以通过它直接建立责任链,省的去遍历strategy_rule表。
(2)strategy_rule表,里面有具体的策略规则(strategy_id和rule_model确定),有具体的rule_value进行解析,执行具体逻辑时根据rule_model匹配查找即可。这里可以匹配针对策略的规则具体值,也可以匹配针对到具体策略奖品的,award_id是个保留字段。
(3)award表,不用多说,对奖品的具体描述。
(4)strategy_award表,对奖品的配置信息,这个表是在规则树中使用的,因为它有规则树用到的rule_model,这个是规则树指定建树的树id。(每一个奖品对应一个特定的规则树)
(5)rule_tree,rule_tree_node,rule_tree_node_line表,三张表构成规则树。rule_tree、rule_tree_node、rule_tree_node_line三张表都有treeId,treeId对应一个规则树,作用于一个奖品。(一个treeId可以把当前树的所有节点,line都给查出来了。)
rule_tree表除了指定了树的一些描述信息以外,还指定了tree_node_rule_key,指定树的根节点是哪个。
rule_tree_node表,指定了rule_key,代表规则,在树的执行引擎中会去匹配树规则处理节点。该节点还有rule_value属性
rule_tree_node_line表,rule_node_from和rule_node_to表示起始节点,rule_limit_value,根据上一个节点的返回结果和该字段比较进行line的匹配,这里继续执行的关键。
其次是活动相关的表:
(1)raffle_activity表,就是活动表,和策略表一样,只是给出了描述性信息。它还包含了strategy_id策略主键(与策略绑定)和状态(是否开启)。
(2)raffle_activity_count表,记录了总库存镜像,月库存,日库存的镜像(?项目里用的是用户账户的库存嘛?)
(3)raffle_activity_sku表,其实就是整合raffle_activity表id和raffle_activity_count表id,把它作为一个最小商品单位,好处是应对场景一个活动配置不同次数的场景,避免严格捆绑次数。sku相当于id。
(4)raffle_activity_account表,用户账户镜像表,非流水表。包含用户id和活动id
(5)raffle_activity_account_day、raffle_activity_account_month:作用是记录日消费和月消费,用来扣除消费剩余的,区别raffle_activity_account表
(6)user_raffle_order表,抽奖订单,用于执行抽奖任务,包含策略id(用于执行后续抽奖),订单id(uuid生成),订单状态(未使用->已使用)
(7)user_award_record表,活动id,策略id,订单id,奖品信息的整合
(8)task表,任务补偿,
4. Q 哪些需要分库,哪些需要分表?
A:单表达到200w,磁盘数据达到几个GB了,一般需要分库分表。
在本项目中,以活动类的配置,比如有哪些策略,有哪些活动,奖品配置这些,不需要分库分表。但是以用户的行为的表,比如活动下单,活动流水,账户等需要分库分表。
一般路由处理用用户id,这样好在一个事务中实现,因为所有的表都能找到。
5. Q 项目中抽奖如何实现O(1)复杂度的?
A:采用时间换空间的办法,通过所有奖品的概率生成一个整数范围的map(数组),存放着奖品的id。抽奖的时候先将该数组在缓存中预热,然后生成一个范围内的随机整数,即可根据整数通过Map直接得到awardId,实现O(1)复杂度抽奖。
6. Q 讲一讲你项目中如何使用责任链模式前置处理抽奖的?什么场景使用它,什么场景使用组合模式?
A:
7. Q 讲一讲你的项目中如何使用规则树处理后置抽奖的?如何通过模板模式串联整个抽奖过程的?
A:为了实现如下的抽奖业务:对于一个特定的奖品,需要首先判断是否超过一定的抽奖次数,如果没超过则进入兜底奖励处理,超过了则再判断是否有库存,如果有库存则进行库存扣减操作,没有库存则继续进行兜底奖励处理。
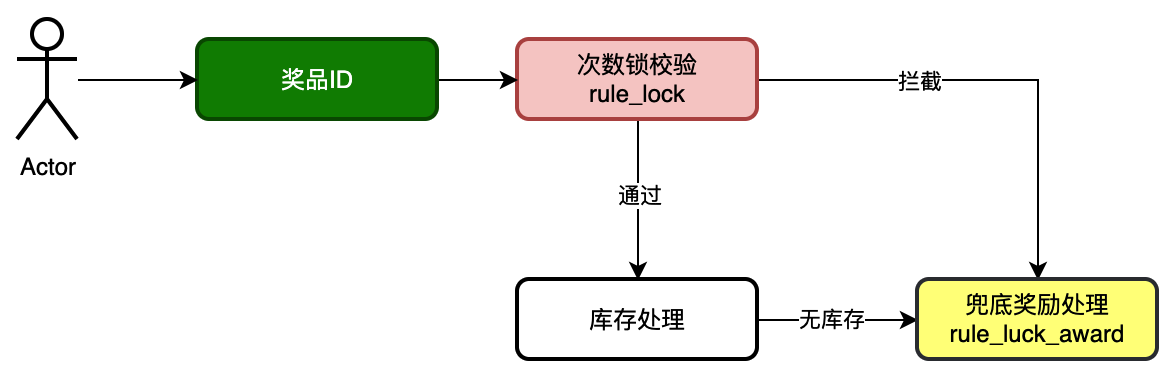
很明显这个抽奖后置规则不是链式调用的,不能通过责任链模式,于是采用树形规则策略。
对于每一指定的strategyId和awardId,rule_model标注了指定的tree_id,制定了当前awardId奖品的后置规则。
// 获取基础信息
String nextNode = ruleTreeVO.getTreeRootRuleNode();
Map<String, RuleTreeNodeVO> treeNodeMap = ruleTreeVO.getTreeNodeMap();
// 获取起始节点「根节点记录了第一个要执行的规则」
RuleTreeNodeVO ruleTreeNode = treeNodeMap.get(nextNode);
while (null != nextNode) {
// 获取决策节点
ILogicTreeNode logicTreeNode = logicTreeNodeGroup.get(ruleTreeNode.getRuleKey());
String ruleValue = ruleTreeNode.getRuleValue();
// 决策节点计算
DefaultTreeFactory.TreeActionEntity logicEntity = logicTreeNode.logic(userId, strategyId, awardId, ruleValue);
RuleLogicCheckTypeVO ruleLogicCheckTypeVO = logicEntity.getRuleLogicCheckType();
strategyAwardData = logicEntity.getStrategyAwardVO();
log.info("决策树引擎【{}】treeId:{} node:{} code:{}", ruleTreeVO.getTreeName(), ruleTreeVO.getTreeId(), nextNode, ruleLogicCheckTypeVO.getCode());
// 获取下个节点
nextNode = nextNode(ruleLogicCheckTypeVO.getCode(), ruleTreeNode.getTreeNodeLineVOList());
ruleTreeNode = treeNodeMap.get(nextNode);
}
// 返回最终结果
return strategyAwardData;首先获得根节点,其中logicTreeNodeGroup.get(ruleTreeNode.getRuleKey())即得到对应规则rule_key的处理节点,经过它返回一个处理结果。根据处理结果ALLOW和TAKE_OVER,走对应的当前node作为nodeFrom的line对应的nodeTo得到下一个节点。如何为空了则返回最终结果。
8. Q 抽奖减库存如何支持高并发量的?不超卖规则如何实现的?
A:抽奖是秒杀业务场景,并发量极高。用mysql的行级锁,业务执行时连接资源被占用无法释放,其他请求也进不来,从而会卡死。如果用mysql的乐观锁,高并发的情况下重试率极高,依然不是一个好的选择。
所以对于这种业务场景,我们会使用redis缓存处理库存。redis本身是单线程执行的,不存在并发问题,而且性能还很高。
但是使用redis的时候依然会有超卖问题,因为Redis默认的持久化方式是RDB,就是保存快照。假如从98库存扣减到96并且在98拍了快照,恢复以后又变成了98,这样会导致超卖问题。对于这种情况,如果我们仍采用一把锁,效率依然很低的。所以这里采用空间换时间的办法,采用redis的分段锁,基于redission的tryLock实现的setNx接口对扣减的库存字段进行兜底。保证不会产生超卖问题。
redis发送扣减通知到延迟队列,用定时任务获取队列内容进行数据库扣减,保证了最终一致性。(该业务场景用不到实时一致性)当然在该项目中的活动库存扣减中的业务中,如果活动库存减为了0,则应该使用MQ发送异步消息通知清空数据库,保证一致性。
这里有疑问,在redis扣减和发送消息到延迟队列之前发生了宕机,是不是会出现少卖问题呢?
9. Q 如何解决重复下活动订单的问题?
A:在活动订单的表中新增了字段out_business_no,并建立了唯一索引。创建订单时使用uuid创建out_bussiness_no,用编程式事务在保存订单信息的时候捕获duplication_key异常并进行回滚。
10. Q 写入中奖记录的时候,需要存库和发MQ,如何模拟事务实现?
A:最终得到抽奖结果并且写入的时候,需要写库并且发MQ消息进行异步通知(让用户更快知道中奖结果)。但是写入数据库和MQ发消息肯定不能通过一个事务实现,这就导致写入数据库之后可能MQ因为网络或者其他原因导致发送不成功。
对于这种情况,采用任务补偿的方式进行处理。
try {
// 发送消息【在事务外执行,如果失败还有任务补偿】
eventPublisher.publish(task.getTopic(), task.getMessage());
// 更新数据库记录,task 任务表
taskDao.updateTaskSendMessageCompleted(task);
} catch (Exception e) {
log.error("写入中奖记录,发送MQ消息失败 userId: {} topic: {}", userId, task.getTopic());
taskDao.updateTaskSendMessageFail(task);
}有一个task表保存所有的MQ任务状态。如果任务发送失败了,try catch中捕获并写入数据库任务状态为失败。在trigger包下有个定时任务SendMessageTaskJob,因为task表只做了分库没有做分表,每个库开一个单独的线程异步执行扫描发送没成功的task,异步执行对task的发送。捕获到异常仍然更新为fai1的task。
11. Q 生产者可能多次发送同一个MQ,如何保证产品不会超发的?
A:仍然是个幂等的设计,MQ的消息包含一个唯一标识的message_id(uuid生成),依然是建立唯一索引。消费者端可以做判断处理。
12. Q DDD模型中的三大对象?
A:
-
aggreate 聚合对象:内部能保证原子性,外部保证事务一致性
-
entity 实体对象:与数据库持久化对象一一对应的
-
valobj 值对象:通常是一些对象的属性值,不会对数据库产生影响