-
- 1.1. 线程基础
- 1.1.1. 创建线程的方式
- 1.1.2. Thread、Runnable、Callable三个接口的区别?
- 1.1.3. 为什么我们调用start()方法时会执行run()方法,为什么我们不能直接调用run()?
- 1.2. 线程有哪些状态?
- 1.2.1. java线程状态与Linux线程状态的区别?
- 1.2.2. wait()和notify()是什么?
- 1.3. Volatile&Synchronized&ReentrantLock&Condition
- 1.3.1. 讲一下synchronized的用法与底层实现
- 1.3.2. 锁升级过程
- 1.3.3. ReentrantLock是什么?AQS是什么?与synchronized的区别?
- 1.3.4. volatile的实现原理?
- 1.3.5. JAVA对象头包括了哪些信息?
- 1.3.6. Condition的用法?
- 1.3.7. ReentrantReadWriteLock是什么?
- 1.3.8. StampedLock是什么?
- 1.3.9. AQS的应用
- 1.4. Atomic&ThreadLocal&CyclicBarrier
- 1.4.1. ThreadLocal是什么?用法和实现?
- 1.4.2. Atomic是什么?用法?
- 1.4.3. 线程池
- 1.1. 线程基础
1. JUC
1.1. 线程基础
1.1.1. 创建线程的方式
a. 继承自Thread类,重写run,start()
b. new Thread(Runnable),重写Runnable接口的run,start()
c. 实现Callable接口,实现call方法,使用FutureTask来包装该线程(因为FutureTask是Runable和Future结合的,Future又是用来存储Callable结果的)。Thread的参数可以接收一个FutureTask,FutureTask
1.1.2. Thread、Runnable、Callable三个接口的区别?
i. 使用继承Thread的方法的局限性在于无法再继承其他类,而且不能用线程池中(threadPool.submit(Runnable()))
ii. Thread的本质是实现了Runnable接口
iii. Callable常用于获取获取返回结果的场景,但是获取结果的get()是阻塞的。callable的优点在于可以抛出异常。
iv. Runnable和Callable的转化:Executors可以实现Runnable对象和Callable对象的转化
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW;
}
public FutureTask(Runnable runnable, V result) {
// 通过适配器RunnableAdapter来将Runnable对象runnable转换成Callable对象
this.callable = Executors.callable(runnable, result);
this.state = NEW;
}1.1.3. 为什么我们调用start()方法时会执行run()方法,为什么我们不能直接调用run()?
如果直接调用run(),则会把run函数作为普通方法来调用,而不会开启多线程
1.2. 线程有哪些状态?
- 六种
- NEW 创建,RUNNABLE 运行,BLOCKED阻塞,WAITING,TIME_WAITING等待,TERMINATED终止
- 当一个线程被创建后为NEW状态,当被调用start()后为RUNNABLE状态(包括RUNNING和READY),抢锁失败后为BLOCKED阻塞状态,调用wait、join、park后进入WAITING,带上时间进入TIME_WAITING状态,终止状态为TERMINATED状态,
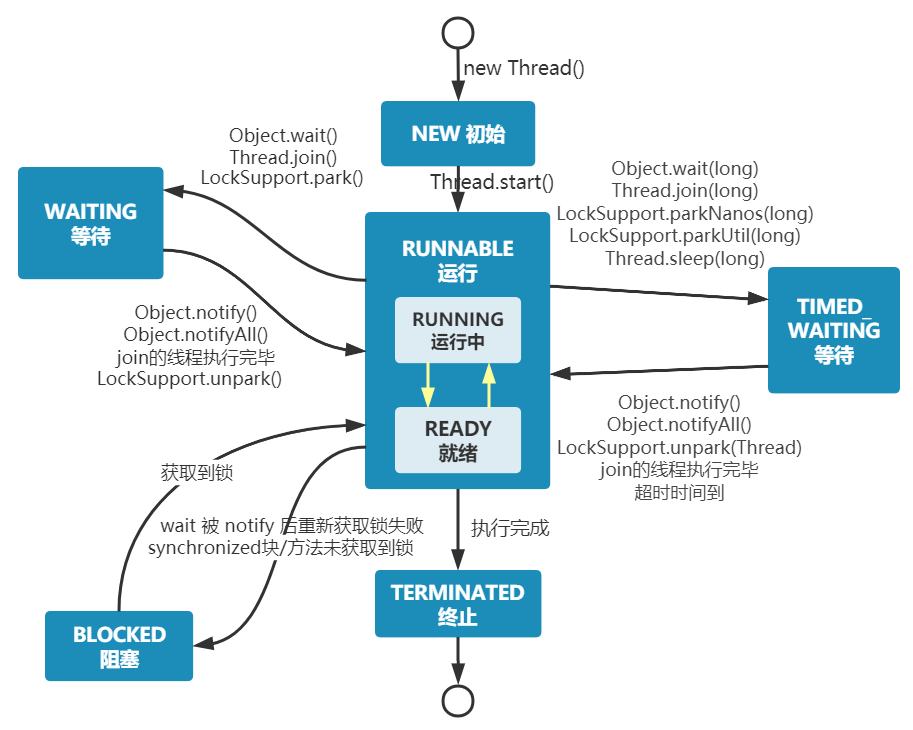
1.2.1. java线程状态与Linux线程状态的区别?
合并
Linux中有Ready和Running状态,而java中将这两个状态合并成了RUNNABLE状态,也就是说,java向开发者屏蔽了OS线程调度的细节,不论一个线程有没有调度到CPU上,开发者看到的都是Runnable状态。
拆分
Java中将OS中的BLOCKED分为了BLOCKED和WAITING状态,这两个OS看来都不会占用CPU资源,但是Java的BLOCKED状态并不会释放锁资源。
1.2.2. wait()和notify()是什么?
wait()是让Object对象释放当前线程的对象锁,进入等待队列,线程进入WAITING状态。(必须和synchronized配合使用,释放的是当前线程获取到的synchronized锁)
wait和notify()的原理
wait():
(1)JVM将当前线程加入到Monitor的waitSet里面,等待被其他线程唤醒
(2)释放Monitor的Owner,让其他线程可以抢占锁
(3)线程状态变为WAITING
notify()/notifyAll():
(1)Monitor唤醒waitSet中第一条(全部)等待的线程
(2)被唤醒后的线程会从WaitSet移动到EntryList,线程具备了排队抢夺Monitor的Owner权利的资格,其状态从WAITING变成了BLOCKED。因为synchronized的非公平性,下次可以抢占锁资源
DEMO:
class A {
private Object obj = new Object();
public void f1() {
synchronized(obj1) {
...
obj1.wait();
...
}
}
public void f2() {
synchronized(obj1) {
...
obj1.notify();
...
}
}
}
}
}请区分一下线程的sleep,yield,wait,join方法
- sleep(time):(1)释放CPU资源,但不释放锁资源(2)需要指定时间,当时间结束后重新运行(3)不考虑线程的优先级(4)调用sleep后进入TIME_WAITING状态(5)InterruptException异常审查捕获
- yield:(1)释放CPU资源,不释放锁资源(2)释放后只给相同优先级的线程CPU调度的机会(3)调用后进入RUNNABLE状态(ready),还有可能重新抢占到CPU
- join:(1)不释放锁资源,阻塞线程直到目标线程执行结束,本质还是基于wait和notify实现的,如果仍然在运行就继续wait()(2)(4)InterruptException异常审查捕获
- wait:(1)释放锁资源,醒来后要重新抢锁(2)调用后进入WAITING状态(3)(4)InterruptException异常审查捕获
Thread的Interrupt()的作用
- 线程处于阻塞状态:Object.wait()、Thread.sleep(time)、Thread.join(),如果interrupt了则抛出InterruptException异常,需要手动捕获并处理(也可以Thread.currentThread.interrupt())重设标志位。
- 线程处于运行状态,则只是将打断标记位置为true,通过isInterrupted()查看自己是否被中断,然后做相应的处理。
守护线程
JVM线程分为用户线程和守护线程,终止方向是用户线程->JVM进程->守护线程
Entrylist和WaitSet是如何实现的?
双向链表,基于JVM的Monitor实现的,每个节点是一个线程,差别在于
- EntryList中的节点是BLCOKED,WaitSet中的节点是WAITING和TIME_WAITING
什么时候用notifyAll什么时候notify?
基于synchronized的等待队列不能设置多个condition(ReentrantLock可以实现多个Condition)
所以等待多个condition的时候因为不知道是哪个condition所以用notifyAll(),而所有线程的等待条件都一样且单进单出的时候用notify()
什么是信号丢失?
线程还没有wait()的时候就调用signal(),signal()的信号丢失了。
解决:唤醒信号存储为类变量
public class SignalLossDemo {
Object monitorObject = new Object();
boolean wasSignalled = false;
public void doWait() {
synchronized (monitorObject) {
if(!wasSignalled) {
try {
monitorObject.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
wasSignalled = false;
}
}
public void doNotify() {
synchronized (monitorObject) {
monitorObject.notify();
wasSignalled = true;
}
}
}什么是虚假唤醒?
线程从wait()中醒来,并不一定是条件满足了(只能一个队列,可能多个condition),或者条件没有满足直接调用了notify,因此会额外增加一些开销
解决:wait()放在循环体内
public class EarlyWakeUpDemo {
Object monitorObject = new Object();
boolean wasSignalled = false;
public void doWait() {
synchronized (monitorObject) {
while(!wasSignalled) {
try {
monitorObject.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
wasSignalled = false;
}
}
public void doNotify() {
synchronized (monitorObject) {
monitorObject.notify();
wasSignalled = true;
}
}
}1.3. Volatile&Synchronized&ReentrantLock&Condition
1.3.1. 讲一下synchronized的用法与底层实现
用法
- 代码块加锁,要拿到指定对象,如果是this那就用当前实例的锁
- 为实例方法加锁,此时拿到的是实例对象this的锁
- 静态方法加锁,拿到的是类的锁
实现
- 指令层面:synchronized同步代码块与同步方法的底层实现 monitorenter/monitorexit(同步代码块), acc_sychronized(accessFlags,同步方法)
- 数据记录在哪里:对象头MarkWord
- 锁的底层实现:
i. 偏向锁:对象的MarkWord记录线程的ID,只能是一个存活的线程,原来线程挂了可以重偏向
ii. 轻量级锁:线程的Lock Record帧记录了对象的MarkWord,MarkWord记录了Lock Record
iii. 重量级锁:JVM C++实现的ObjectMonitor,关键数据结构Cxq(入队前CAS自旋是不公平锁的原因),还有个EntryList,WaitSet。其他还有ownerThread和线程重入次数(可重入锁)。ObjectMonitor的ownerThread是持有锁的线程,MarkWord是Monitor地址,Lock Record是MarkWord。
1.3.2. 锁升级过程
偏向锁
原理:锁之间不存在竞争,只有一个存活的线程占有该对象的锁。
加锁过程
- MarkWord是否为可偏向状态,即是否为1,且锁标识位为01
- 测试当前线程ID是否是当前线程ID,如果是则执行同步代码块
- 不是则执行CAS,如果线程ID是空的则MarkWord改为当前线程ID
- 如果线程ID是别的线程ID,看那个线程是否还存活,如果不存活则重偏向,如果存活则撤销那个线程偏向锁,升级为轻量级锁
偏向锁的撤销
- 在一个安全点停止拥有锁的线程
- 遍历线程的栈帧,检查是否有Lock Record。如果有,就要清空Lock Record并且将MarkWord重置以变为无锁状态。
- 将当前锁升级为轻量级锁
- 唤醒当前线程
延迟偏向
一开始5s时JVM加载java类,加偏向锁再撤销会浪费。
什么是批量重偏向,什么是批量撤销?
批量重偏向:线程1创建了N个对象,一开始开启了偏向锁的这N个对象,线程2又去访问这N个对象,访问过程中这N个对象因为发生线程竞争而变为轻量级锁,当第20次的时候JVM会认为一开始重偏向错了,所以以后创建的对象改为偏向线程2的偏向锁了。
批量撤销:线程1创建40个,全是偏向线程1。线程2加锁这40个,前20个轻量,后20个偏向t2(撤销了40次)。线程3再加锁,对象变为不可偏向状态。以后新创建的对象也变为不可偏向状态。
轻量级锁
原理:本质是自旋锁,一般用于锁竞争不是很激烈的时候
加锁流程:
- 栈帧创建一个Lock Record,记录MarkWord拷贝,MarkWord记录Object的地址
锁升级过程:
- CAS尝试加轻量级锁,不成功说明其他线程已经加上轻量级锁了,自旋一定次数,如果还是失败了则升级重量解锁
- 升级重量级锁的过程是申请Monitor,MarkWord指向Monitor地址,Monitor的OwnerThread指向当前线程。
普通自旋锁和适应性自旋锁
普通自旋锁自旋次数固定(默认10)
适应性自旋锁根据上次加锁自旋次数动态改变下次自旋次数,越激烈就自旋越少次
重量级锁
数据结构:Cxq(其实可以忽略,不重要),EntryList,WaitSet,OwnerThread
因为涉及信号量和互斥锁,涉及到到用户态到内核态的切换,开销大
为什么是非公平锁?
新线程加进Cxq队列之前会先进行一次CAS尝试,所以是非公平锁
entryList和waitSet
wait()进入waitSet,被唤醒后进入entrylist。线程抢锁失败进入entryList
1.3.3. ReentrantLock是什么?AQS是什么?与synchronized的区别?
AQS的实现?
AQS同步器,提供了FIFO双向链表和volatile修饰的state变量。
AQS用了模板方法:
-
acquire()里面先调用钩子方法tryAcquire()实现对state变量的修改,成功抢到锁,如果失败则调用addWaiter()加入队列。addWaiter()通过CAS将已经被封装成Node的线程加入队尾,加入队尾后调用acquireQueued()不断在前驱节点自旋,如果上一个节点是头节点则尝试获得锁,如果上一个节点不是头节点则park()住,等待前一个节点将它唤醒。唤醒后重新进入acquireQueued()的自旋抢锁。
-
release()里面首先调用了tryRelease()钩子方法,对state变量进行修改,然后unpark()唤醒其后继节点。后继节点唤醒后又进入acquireQueued()自旋,在这里面完成出队操作。
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}ReentrantLock的实现?
用处:
- 支持公平锁和非公平锁
- 能够设置阻塞时间(lock.tryLock(5, TimeUnit.MICROSECOND))
原理:
ReentrantLock基于AQS实现,重写了tryAcquire()和tryRelease()。tryAcquire()是CAS让state + 1,tryRelease()是CAS让state - 1。
可重入的体现:
tryAcquire()中如果发现是持有锁的线程,会让state累加。tryRelease()释放锁的时候如果持有锁的线程,会让state减1。
公平锁和非公平锁的体现?
FairSync和NonFairSync有不同的tryAcquire()的实现。非公平锁每次lock()进入tryAcquire()都会先进行CAS操作加锁,公平锁则增加了hasQueuedPredecessors()函数判断队列中有没有前继节点,如果当前线程是队列头节点则可以抢,否则不能抢。
ReentrantLock可打断的实现?
支持可打断和不可打断的。可打断是指的一个线程在获取锁的过程中,另一个线程可以调用interrupt方法打断该线程。不可打断指的是,哪怕一个线程调用了interrupt,该线程也不会被中断。
- 不可打断模式:
park()之后检查如果被中断过,只是将局部变量interrupted置为true返回给上层acquire(),由acquire()处理,不会影响到acquireQueued()的循环执行。
- 可打断模式:
static final class NonfairSync extends Sync {
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg); // 该函数类似于acquireQueued(),如果park()之后检查到被park()了,则抛出中断异常。
}
Reentrantlock非公平锁释放的过程
释放锁成功,将当前的exclusiveOwnerThread置为null,Sync的state置为0,当前队列不为null则进入unparkSuccessor(),将head的下一个Node的线程给unpark()。这时该线程又会进入acquireQueued()进行tryAcquire()获取锁。
源码总结
public void acquire(...) {
if (!tryAcquire(...) &&
acquireQueued(addWaiter(...))
}
public acquireQueued(...) {
for(;;;) {
if(p == head && tryAcquire(...)) {
// 出队
break;
}
park();
}
}ReentrantLock与Synchronized的区别?
相同
可重入锁,同一线程多次加锁和释放锁
不同
- synchronized依赖于JVM,需要os实现,开销大。ReentrantLock是JDK层面实现。
- Reentranlock可以实现公平和非公平锁,synchronized是非公平锁
- 可以设置抢占阻塞时间
- 等待可中断:即正在等待的线程可以选择放弃等待,改为处理其他事情,通过lock.lockInterruptibly()来实现这个机制
- ReentrantLock + Condition实现不同条件通知,synchronized相当于只有一个condition
1.3.4. volatile的实现原理?
用处
- 可见性:JMM层面指每个线程的工作内存都是最新的,CPU层面是cache是最新的
- 有序性:JVM层面和CPU层面指令禁止重排序(并发情况下会出现指令重排序)
- 原子性:不能保证
底层实现
- CPU层面可见性:lock前缀指令要求修改变量后所在缓存立即写回系统主存。并且要求根据MESI协议,通过CPU嗅探总线上其他CPU是否由该缓存,将其置为无效,以后要重新从主存获取。
- CPU层面有序性:lock前缀指令还有一个作用是加内存屏障,禁止内存屏障前后的指令重排序
- JMM层面可见性:线程的工作内存修改后强制刷新到共享内存
- JMM层面有序性:Happens-before原则
happens-before原则
前一个操作的结果对下一个操作可见
- volatile变量规则:对一个变量的写操作先行发生于后一个变量的读操作
- 线程启动规则:Thread的start方法先于此线程的每一个操作
- 传递规则:A先于B,B先于C,则A先于C
- 锁定原则:unlock先于对它后续的lock
- as-if-serial规则:同一个线程中,有依赖关系的先发生于后。换句话说,单线程运行一定保证结果不变。
与synchronized的比较
volatile仅仅保证可见性和有序性,synchronized可以保证可见性、有序性和原子性
1.3.5. JAVA对象头包括了哪些信息?
- MarkWord:锁信息
- Class Metadata Address:指向方法区中类元数据
- 数组的长度(如果是数组)
Mark Word

1.3.6. Condition的用法?
Condition的等待队列是单向链表,但是还是记录了一个首尾节点
Lock.newCondition()创建一个新的等待队列
AQS同步队列和等待队列是聚合关系,只能一个同步队列,可以多个等待队列
await()流程
- 创建线程封装的Node加入等待队列尾
- 释放锁,唤醒AQS同步队列头节点后的那个节点
- while中park(),直到park唤醒并且检查到节点离开等待队列重新回到同步队列,退出while循环
- 调用accquireQueued()不断尝试获得锁
伪代码:
public void await() {
addConditionWaiter(); // 加入等待队列
release(...); // 唤醒头节点下一个
while(!isOnsyncQueue(...)) {
park(); // 唤醒后看是否已经从等待队列到同步队列中了
}
acquireQueued(); // 里面还是park(),即自旋+阻塞
}signal()流程
-
enq()将等待队列头部放入AQS同步队列尾部
-
唤醒当前线程,从park()之后执行,即正常进入同步队列中的阻塞等待(acquireQueued)
总结
ReentrantLock的acquire()和release()是进入同步队列中的acquireQueue()进行自旋+阻塞。condition相当于进入等待队列中进行自旋+阻塞,如果唤醒并离开while循环(说明已经在同步队列了),则重新进入同步队列中的acquireQueue()进行自旋+阻塞。
1.3.7. ReentrantReadWriteLock是什么?
支持读写锁,读锁可重入,写锁不可重入
lock.readLock() lock.writeLock()
为什么只支持锁降级,不支持锁升级?
- 为什么支持锁降级:假如已经获得了写锁,写锁是只有一个线程才能持有,降级为读锁不受影响
- 为什么不能锁升级:锁升级是读锁升级为写锁。但是读锁可能有多个,升级为写锁需要等待所有读锁都释放,这就可能出现互相等待。
总结为:因为写锁只能一个线程持有,读锁可能多个线程持有。
1.3.8. StampedLock是什么?
是对ReentrantReadWriteLock的一种改进,主要改进为读锁如果没有竞争,不会加锁。底层原理是CLH队列,不具体讲了。
具体为三种情况:
- 悲观读锁:与ReadWriteLock的读锁类似,多个线程可以同时获取悲观读锁,悲观读锁是一个共享锁
- 乐观读锁:直接操作数据,不加任何锁
- 写锁:与ReadWriteLock的写锁类似,写锁和悲观读锁是互 斥的。
1.3.9. AQS的应用
ReentrantLock
tryAcquire()是CAS让state + 1,tryRelease()是CAS将state - 1,只有state = 0才有机会让其他线程获取到锁。
CountDownLatch
任务划分为N个子线程执行,对应于state的值。每个子线程执行完countDown()以后CAS使得state - 1,等待所有子线程执行完以后(state = 0),unpark()掉主线程,主线程从await()处唤醒继续执行。
Semaphore(信号量)
state是剩余的许可。如果 state >= 0 的话则获取成功。支持公平和非公平。
1.4. Atomic&ThreadLocal&CyclicBarrier
1.4.1. ThreadLocal是什么?用法和实现?
每个线程的变量副本
实现
每个Thread都有一个ThreadLocalMap变量,ThreadLocalMap的key是ThreadLocal,value是对应的值
ThreadLocalMap解决hash冲突的方式采用的是线性探测法,如果发生冲突会继续寻找下一个位置
ThreadLocal内存泄漏问题?怎么解决的?
原因是ThreadLocalMap中,entry是弱引用(防止不用的ThreadLocal占用内存),value是强引用。所以GC了就会出现key变为null的entry,导致内存泄漏。
解决是每次ThreadLocal用完后手动remove()
ThreadLocal的使用场景
- 线程间数据隔离
- 绑CPU,增加CPU的亲和性,避免了上下文切换刷新TLB的开销。(避免CPU切换的开销)
如果子进程要调用父进程的ThreadLocal怎么办?InheritableThreadLocal?怎么跨线程传递参数?
InheritableThreadLocal 的存储机制和 ThreadLocal 是一样的,区别在于复写了 createMap 和 getMap
他在 createMap 的时候会调用 ThreadLocalMap(parentMap) ,父线程的变量值赋值给子线程
1.4.2. Atomic是什么?用法?
基本类型:AtomicInteger、AtomicLong、AtomicBoolean、AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray、AtomicReference、AtomicMarkableReference、AtomicStampedReference
- AtomicXXXX:如AtomicInteger和AtomicLong,可以原子执行+1/-1操作,API如getAndIncrement(),getAndDecrement(),compareAndSet()
- AtomicXXXXFieldUpdater:可以无入侵的对类中的某个元素进行原子性的加减,但是要求被加减的元素必须是volatile的。API,new AtomicReference
(),其他接口一样。 - AtomicXXXXArray:对各种数组的原子操作,针对某下标。API接口:getAndSet(int i, int newValue),getAndIncrement(int i),getAndDecrement(int i),compareAndSet(int i, int except, int update)
AtomicInteger原理
- 读数据的原理:使用getIntVolatile(Object obj, long offset)来获取对象的内存offset处的值。这是UnSafe包的原子操作。
- 修改数据原理:底层使用UnSafe包的本地方法(CPU原子操作)this.compareAndSwapInt来实现。
- 变量可见性:变量使用volatile修饰,保证可见性
Java里面哪里用到了CAS?
- Atomic/UnSafe类:AtomicInteger、AtomicLong、AtomicReference使用CPU的CAS原子操作
- ConcurrentHashMap接口:使用CAS实现线程安全的并发访问
- AQS:CAS操作实现对state的更新和线程等待唤醒
- 线程池:java的线程池通过CAS操作实现线程的启动和终止
CAS有什么问题?解决方案?
ABA问题
问题:初始50,改为100,又改为50
解决方案:
AtomicStampedReference以及AtomicMarkableReference支持两个变量上执行原子的条件更新,但大多数情况下没有必要解决这个问题。
循环时间开销大
问题:循环时间开销大,如果没有获取到目标值就会一直自旋重试
解决方案:设置threshold,到该值时就停止
LongAdder和AtomicLong有什么区别?LongAdder的区别?
实现
- AtomicLong底层依靠CAS来保证原子性的更新,但是在并发很高的时候会不断尝试,开销大
- LongAdder采用的是一个Cell数组,借鉴了ConcurrentHashMap的分段锁的思想,里面维护了一个volatile的变量base,在没有并发(指CAS成功)的时候只是base上加,当CAS失败了,就在cell数组中(没有则创建)计数,最后有个sum()函数会把所有的技术累加。(但是sum()的过程中不会阻塞计数,所以只是实现最终一致性)
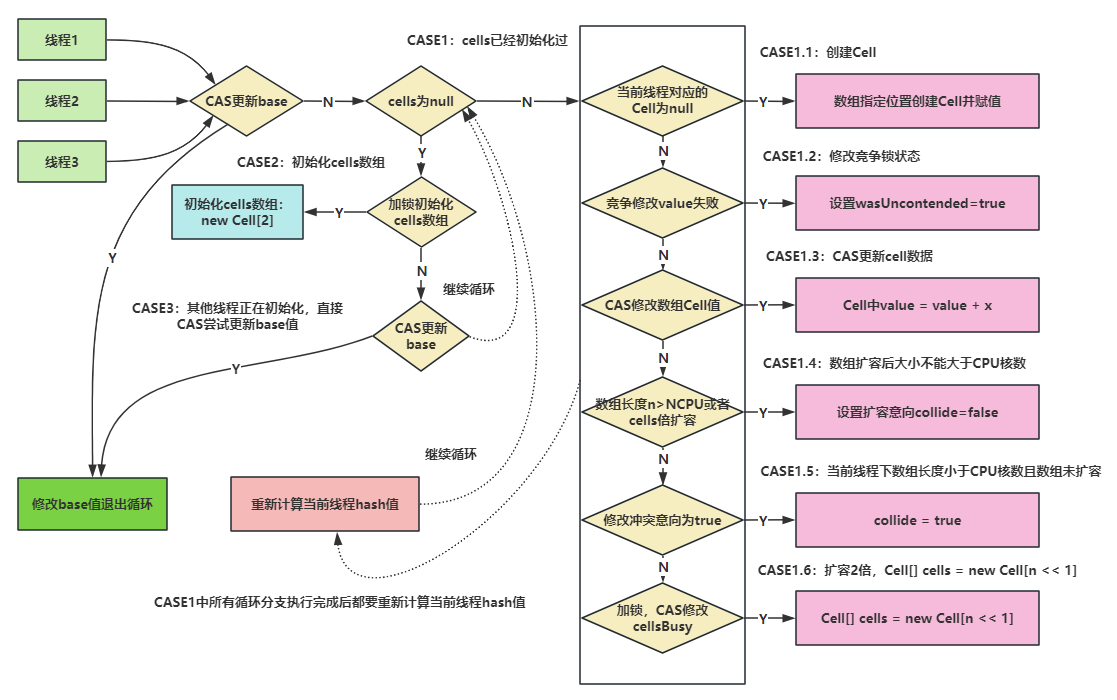
什么是CyclicBarrier?与CountDownLatch的区别?
CyclicBarrier也是一种线程同步工具,初始化时指定其容量大小,调用await()让计数-1并阻塞,当计数为0时释放线程
区别
- 是否可以复用:CyclicBarrier是可以复用的,如果减小为0,会reset。但是CountDownLatch不会复用,需要重新new一个
- 用途不同:CountDownLatch主要用于主线程等待其他线程完成任务,CyclicBarrier主要用于同步线程状态,当各个线程到达某个同步线程状态时再开始执行
1.4.3. 线程池
线程池创建?参数的含义?为什么不直接用executors?runnable的类型?
最重要的三个参数描述线程池的大小
- corePoolSize:核心线程的大小,创建线程池后不会立即启动。任务提交的时候才会启动线程(大于等于corePoolSize)
- workQueue:任务队列
- maximumPoolSize:最大线程数,核心线程数满且阻塞队列满且阻塞队列满的时候才会判断这个
两个用于空闲线程存活的时间相关的参数
-
keepAliveTime:线程数大于核心数,多余的空闲线程最多的存活时间
-
Unit:存活单位
剩下一个threadFactory,一个拒绝策略
-
threadFactory:产生线程的factory,用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。
-
rejectExecutionHandler:拒绝策略
(1)AbortPolicy中止策略:抛出一个RejectedExecutionException异常
(2)DiscardPolicy抛弃策略:放弃本次任务
(3)DiscardOldestPolicy抛弃最旧的策略:抛弃最旧任务
(4)CallerRunsPolicy调用者运行策略:让调用者运行任务
(5)可以自定义拒绝策略,需要重写RejectedExecutionHandler的接口,重写其中唯一的方法rejectedExecution即可
executors是什么?为什么不用executors创建?
- FixedThreadPool:<1>核心线程数等于最大线程数<2>阻塞队列是无界的
- SingleThreadPool:<1>核心线程数和最大线程数固定为1<2>阻塞队列是无界的
- CachedThreadPool:<1>核心线程数为0,最大线程数是Integer.MAX_VALUE<2>阻塞队列为0
- ScheduledThreadPool:<1>支持定时和周期任务,使用的DelayedWorkQueue<2>最大线程数是Integer.MAX_VALUE
任务调度线程池是什么?与Timer的区别?
ScheduledThreadPoolExecutor本身是一个线程池,支持并发执行。其内部使用DelayedWorkQueue作为任务队列。
1. Timer的优缺点? Timer也是任务调度,Timer.schedule(TimerTask, delay),但是所有任务都由一个线程来调度,因此是串行执行的,前面的线程可能会影响后面的。
- ScheduledThreadPool与Timer的差别?
单线程执行和多线程执行
- 任务调度线程池的常用方法
a. 延迟 schedule()
b. 延迟+固定频率 scheduleAtFixedRate()
// 初始延迟时间为1秒,固定频率为3秒
executorService.scheduleAtFixedRate(() -> {
// 执行任务逻辑
System.out.println("任务执行时间:" + System.currentTimeMillis());
}, 1, 3, TimeUnit.SECONDS); b. 延迟+固定时延,时延是上一次任务终止到下一次任务开始 scheduleAtFixedDelay(),接口参数同scheduleAtFixedRate()
每种线程池可能OOM的原因?
-
FixedThreadPool 和 SingleThreadExecutor : 允许阻塞队列的长度为为 Integer.MAX_VALUE,可能堆积⼤量的请求,从⽽导致OOM。
-
CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE,可能会创建⼤量线程,从⽽导致OOM。
ForkJoin线程池是什么?
非常像MapReduce的一集,ForkJoinPool使用了分治的思想,将一个大任务拆分成多个小任务,并且在分治的基础上加入了多线程,可以把每个任务的分解Fork和合并Join交给不同的线程来完成。ForkJoinPool会创建和CPU核心线程数相同的线程池。
使用方法:
- 写一个任务类,继承自RecusiveTask类,泛型是返回值类型
- 重写RecusiveTask类的compute()方法,调用fork()进行计算,join()合并计算结果
- forkJoinPool调用invoke()方法传递任务对象,接受一个RecursiveTask类型任务对象
DEMO:CSDN自己查吧
线程数的设置
最大线程数的设置:
- CPU密集型:n+1。CPU密集的意思是该任务需要大量的运算,而没有阻塞,CPU一直全速运行。+1是因为防止thread因为缺页等原因陷入中断。
- IO密集型:n*2,由于IO密集型任务的线程不会一直在执行任务,所以多分配一些线程数
核心线程数的设置:
核心线程数 = 最大线程数 * 20%
runnableQueue有几种类型?
- 无界:
LinkedBlockingQueue:<1>一个基于链表结构的阻塞队列<2>注意不要囤积大量的请求,否则会造成OOM<3>newFixedThreadPool()和newSingleThreadPool使用了这个队列
- 有界:
ArrayBlockingQueue:<1>是一个基于数组的有界阻塞队列。内部通过两个condition(notEmpty和notFull)+循环数组的方式实现。add()失败抛异常,put()失败阻塞,offer()失败返回false。poll()失败返回null,take()失败阻塞。
PriorityBlockingQueue:<1>一个具有优先级的无限阻塞队列,内部使用堆和自定义的比较器comparator来实现优先级比较<2>newSheduleThreadPool使用delayedWorkQueue
-
同步:
SynchronousQueue:<1>队列大小为0。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态 <2> newCachedThreadPool使用了这个队列。
提交线程有哪些方法?
- execute()方法用于提交不需要返回值的任务
- submit()方法用于提交需要返回值的任务,线程池会返回一个Future类型对象(FutureTask),可以通过Future.get()阻塞获得返回值。
- invokeAll()方法接收一个Callable对象的集合,提交其中的所有任务
- invokeAny()方法也接收一个Callable对象的集合,哪个任务先执行完毕,返回此任务的结果,其他任务取消
execute()执行的流程
- 第一步判断是否小于corePoolSize,如果小于就创建线程(这一步要获取全局锁)
- 否则判断BlockedQueue是否满了,如果没满就加入BlockedQueue
- 否则判断是否到了maximumPool的size,如果没满就创建线程
- 否则根据饱和策略来处理
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// 如果线程数小于基本线程数,则创建线程并执行当前任务
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
// 如线程数大于等于基本线程数或线程创建失败,则将当前任务放到工作队列中。
if (runState == RUNNING && workQueue.offer(command)) {
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
// 如果线程池不处于运行中或任务无法放入队列,并且当前线程数量小于最大允许的线程数量,
// 则创建一个线程执行任务。
else if (!addIfUnderMaximumPoolSize(command))
// 抛出RejectedExecutionException异常
reject(command); // is shutdown or saturated }
}核心线程什么时候初始化?
默认情况下,创建线程池之后,线程池中是没有线程的,需要提交任务之后才能创建线程。
如果想线程池创建后立即创建线程,可以通过以下两个方法:
prestartCoreThread():初始化一个核心线程
prestartAllCoreThread():初始化所有核心线程
如何获取Executor的报错?
如果是execute()方法,可以直接使用try-catch捕获异常
如果是submit(),可以使用future类的get方法,如果有异常则会返回报错信息
ThreadPoolExecutor是如何表示线程池状态的?
int使用高3位表示线程状态,低29位表示线程数,存在一个原子变量ctl,使用一个CAS操作赋值
线程池有五种状态:
- RUNNING状态:可以接收新任务,可以处理阻塞队列的任务
- SHUTDOWN状态:不可以接收新任务,但可以处理阻塞队列的任务
- STOP状态:中断正在执行的线程并抛弃阻塞队列的任务
- TIDYING状态:任务全部执行完毕,活动线程为0即将进入终结
- TERMINATED状态:终结状态

关闭线程池的两种方法/关闭线程池时如果有任务怎么办?
shutdown()
开始结束线程池,新的任务加入会被拒绝策略中止,但是还要等待任务队列中的所有任务执行完。
shutdownNow()
立即结束线程池,给每个正在执行的线程发送interrupt,并将所有任务队列中的任务通过一个list返回。