-
- 1.1. HTTP报文结构
- 1.2. HTTP状态码(大三美团一面)
- 1.3. HTTP1.0的问题?1.1的解决方法?1.1的问题?2.0的解决方式?3.0有哪些改进?
- 1.4. HTTP和HTTPS的区别?
- 1.4.1. TLS和SSL区别
- 1.4.2. TLS握手流程
- 1.4.3. GET和POST的区别
- 1.4.4. 安全
-
- 2.1. TCP和UDP的区别
- 2.1.1. UDP如何做到可靠传输
- 2.1.2. TCP和UDP的头部格式
- 2.2. 三次握手
- 2.2.1. 过程?
- 2.2.2. 为什么三次握手?
- 2.2.3. 第一、二、三次握手报文丢失了怎么办?
- 2.2.4. 什么是SYN攻击?
- 2.2.5. TCP建立后把网线切掉会发生什么?(客户端主机突然故障了)
- 2.2.6. TCP建立后服务端进程崩溃了会发生什么?
- 2.3. 四次挥手
- 2.3.1. 过程?
- 2.3.2. 为什么不能三次挥手?
- 2.3.3. 为什么TCP的第二次挥手之后客户端进入FIN_WAIT_2状态?
- 2.3.4. 第一、二、三、四次挥手失败了怎么办?
- 2.4. TIME_WAIT状态
- 2.4.1. 大量TIME_WAIT的原因
- 2.4.2. TIME_WAIT为什么要等待2MSL
- 2.5. CLOSED_WAIT状态
- 2.5.1. 什么时候会出现大量的CLOSED_WAIT状态?
- 2.5.2. 出现大量的CLOSED_WAIT有什么影响?
- 2.6. Socket编程
- 2.6.1. Socket的API
- 2.6.2. 体现在三次握手上?
- 2.7. 如何保证可靠性的?
- 2.8. MSS&MTU&MSL
- 2.9. TCP中的粘包问题
- 2.10. DNS和CDN
- 2.1. TCP和UDP的区别
-
- 3.1. IP数据包的格式
- 3.2. IP地址的结构
- 3.2.1. C 类地址哪些是保留地址
- 3.2.2. 三级结构?子网掩码
- 3.3. 使用子网掩码转发IP分组
- 3.4. CIDR
- 3.5. IP协议相关的技术
- 3.6. IPV6如何解决IP枯竭的问题
-
- 4.1. SQL注入
- 4.2. DDoS攻击/洪范攻击
- 4.3. XSS攻击
- 4.4. 中间人攻击
- 4.5. CSRF
-
- 5.1. Reactor 和 Proactor
- 5.1.1. 单Reactor单进程/线程
- 5.1.2. 单Reactor多进程/线程
- 5.1.3. 多Reactor多进程/线程
- 5.1.4. Proactor
- 5.1. Reactor 和 Proactor
-
- 杂题
- 6.1. URI和URL的区别?
- 6.2. PING发生了什么?
- 6.3. 访问www.google.com发生了什么?
- 6.4. 什么是一致性hash?
- 杂题
1. HTTP
1.1. HTTP报文结构
1.1.1. 请求报文
第一部分:方法名(GET/POST) + URL + 版本号
比如 GET baidu.com HTTP/1.1
第二部分:首部字段名 + 字段值(kv)
- connection = keep-alive / close 是否使用长连接
- cookie = 存一些维护登录的id,比如sessionId
- host = 指定被请求资源的Internet主机资源和端口号
- cache-Control = 缓存控制(包含 no-cache 不适用缓存,max-age 限定存在时间的资源 …)
- expire = 允许存在的时间,等同于 max-age 但是优先级低于 max-age
- Accept = 允许接收的数据类型
第三部分:数据,post方法数据比较流行json
1.1.2. 响应报文
第一部分:Version + 状态 + 短语,例如 HTTP/1.1 200 OK
第二部分:首部字段名 + 字段值(kv)
- Content-Length 数据长度
- Content-Type 数据类型
- Date 服务器产生并发送该响应报文的时间
- Last-modified 数据最后修改时间
- cache-Control 缓存控制
以下若干行:数据,常见交互格式如json
1.2. HTTP状态码(大三美团一面)
- 1xx: 服务器收到请求, 需要请求者继续操作
- 100: 客户端应继续该请求
- 101: 服务端根据客户的请求切换协议
- 2xx: 成功
- 200: 请求成功
- 201: 请求成功并创建了新的资源
- 202: 已接受但未处理完成
- 204: 请求成功但未返回内容
- 206: 服务器成功处理了部分 GET 请求
- 3xx: 重定向
- 301: 永久移动, 请求的资源已经被永久移动到新的 URI, 浏览器自动重定向, 并且今后的请求都用新的 URI
- 302: 临时移动, 请求的资源已经被暂时移动到新的 URI, 浏览器自动重定向, 今后的请求沿用旧的 URI
- 300: 多种选择, 请求的资源可包括在多个位置
- 🌟304: 未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。 ( 通过一个头信息指出客户端希望只返回在指定日期之后修改的资源 )
- 4xx: 客户端错误, 请求包含语法错误或无法完成请求
- 400: 客户端语法错误, 例如请求时有一个必须的字段没有传.
- 403: 权限校验不通过
- 404: 服务器无法根据客户端的请求找到资源
- 405: 客户端请求的方法错误,看一下接口是post,但是请求写成了get
- 401: 客户端要求用户进行身份认证
- 408: 请求超时
- 5xx: 服务器错误
- 500: 服务器内部错误, 执行过程中发生了错误
- 501: 服务器不支持的请求, 无法完成请求
- 503: 由于超载或系统维护, 服务器暂时无法处理客户端的请求
- 🌟504: 网关超时
- 505: 服务器不支持请求的 HTTP 协议版本, 无法完成处理
- 521:WebServer Is Down,WebServer停止服务(但其实更多时候是因为根本没找到服务器)
- 522: 连接超时。在OJ项目中,获取提交状态,如果判题服务器一直没有判完,则会出现522错误
转发和重定向有什么区别?
请求转发, 是服务器完成的, 整个过程都是一个请求, 一个响应
重定向是要返回到客户端一个 301 或者 302 的响应, 由客户端重新请求的
1.3. HTTP1.0的问题?1.1的解决方法?1.1的问题?2.0的解决方式?3.0有哪些改进?
1.3.1. HTTP1.1
解决
HTTP1.1支持长连接,connection = keep-alive
缺点
- HTTP队头阻塞:HTTP1.1是对每个域名开FIFO来处理,如果一个HTTP请求发出来响应迟迟不来,就会阻塞后面的请求
- 头部冗余:采用的文本格式,首部未压缩,首部未压缩,而且每一个请求都会带上cookie、user-agent等完全相同的首部。
- 请求并发:HTTP 1.1版本请求并发依赖于多个TCP连接,建立TCP连接成本很高,还会存在慢启动的问题。虽然HTTP/1.1管线化可以支持请求并发,但是浏览器很难实现,chrome、firefox等都禁用了管线化。
1.3.2. HTTP2.0
解决
- 头部压缩:client和server维护缓存头部
- 二进制分帧:首部和数据分为二进制帧
- 多路复用:同一stream可以同时发送多个帧,接收的时候可以同时接收不同响应的帧,根据stream号重组。
缺点
- 无法解决TCP队头阻塞
1.3.3. HTTP3.0
- TCP改为了UDP,应用层基于QUIC,不影响表示层使用TLS 1.3(安全性也更高)
- QUIC相比于TCP建立连接更快
1.4. HTTP和HTTPS的区别?
区别
- HTTP 的传输的数据都是没有加密的, 在途中可以拦截; HTTPS 使用了 SSL 协议进行加密传输
- HTTP 默认的端口是 80; HTTPS 默认的端口是 443
- HTTPS 需要多次握手, 并且消耗 CPU 资源, 页面加载的时间延长, 并且对服务器资源消耗较大
1.4.1. TLS和SSL区别
TLS SSL 都是一种实现安全连接的协议, TLS 是 SSL 的加密版本升级版,目前常用的都是 TLS 1.2
1.4.2. TLS握手流程
- client向server发送ClientHello请求,包括client支持的TLS版本号,加密算法,client random
- server回复ServerHello,包括支持的SSL版本,加密算法等信息,server random,并发送CA公钥
- 客户端对服务器的CA公钥进行认证,并产生一个随机数,用这个随机数,client random和server random作为会话密钥,用服务器公钥加密这个随机数后发送给服务端
- 服务器收到公钥加密的密钥后,用私钥解密,获取会话密钥
什么是对称加密?什么是非对称加密?HTTPS是对称加密还是非对称加密?
对称加密和非对称加密取决于密钥的数量
-
对称加密只有一个密钥,通信的双方使用该密钥来进行解密
-
非对称加密有两个密钥,一个公钥一个私钥,加密方使用公钥加密,解密方法使用私钥解密
HTTPS:
对称加密相比于非对称加密效率高,但是安全性低。四次握手是非对称加密,实际传输使用对称加密。
CA证书的下发和客户端的认证
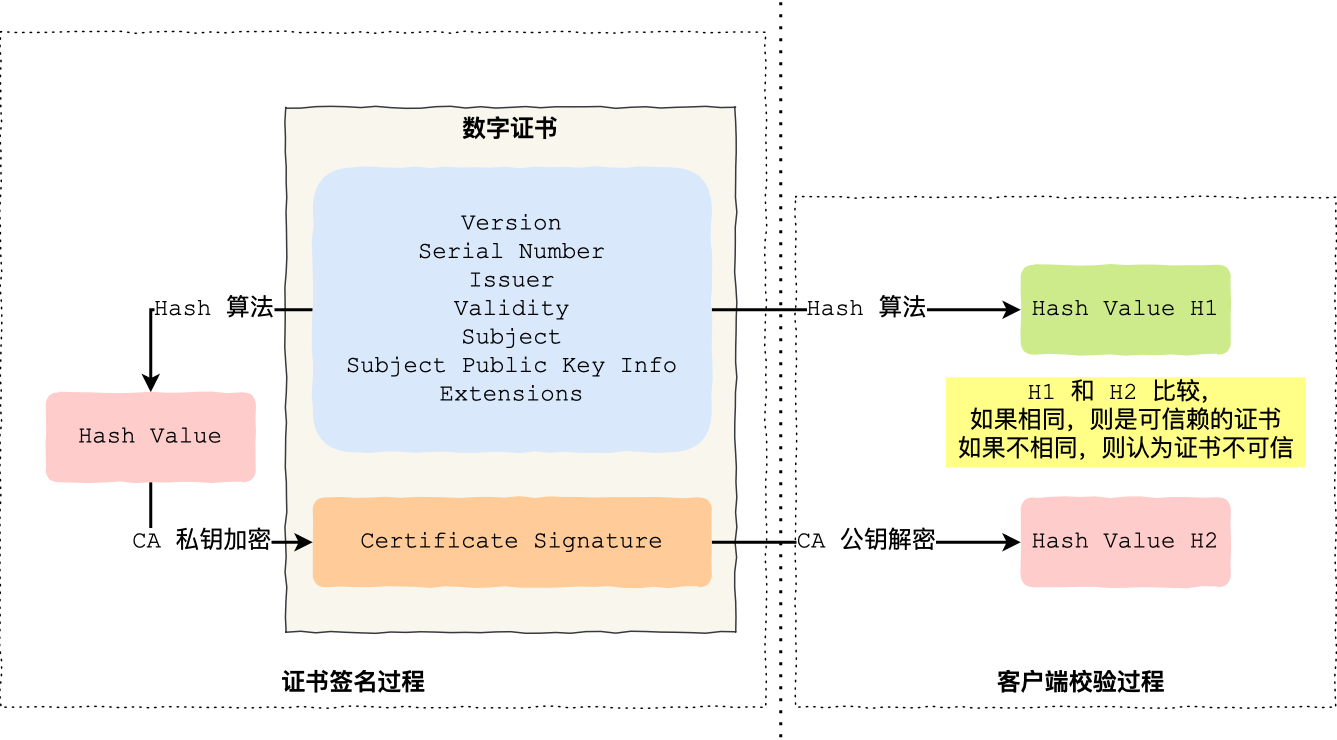
CA机构将Version,序列号等通过hash算法加密,得到hash value,并用CA私钥加密,获得签名放到CA证书上。
client用CA公钥将签名解密得到H1,再与hash算法算出来的H2比较。相同则证明此公钥没有被篡改过。
1.4.3. GET和POST的区别
相同
底层使用TCP传输数据
不同
- 幂等性:GET具有幂等性,多次GET都是一样的。POST会对数据做修改
- 请求长度:POST没有限制,GET有限制
- GET的数据可以被缓存,POST的数据不能被缓存(原因就是幂等性)
1.4.4. 安全
- POST 比 GET 安全, 因为数据在地址栏上不可见
- 然而, 从传输的角度来说, 他们都是不安全的, 因为 HTTP 在网络上是明文传输的, 只要在网络节点上捉包,就能完整地获取数据报文。只有使用HTTPS才能加密安全
2. TCP
2.1. TCP和UDP的区别
a. 是否需要建立连接
b. 是否是可靠传输 TCP有滑动窗口,流量控制,拥塞控制
c. 是否有确认机制 TCP有ACK机制
应用:TCP主要用于常见的网页应用,UDP常用于直播、媒体(网络时延要求高,但是可靠性不高,丢几帧也没关系)
2.1.1. UDP如何做到可靠传输
参考QUIC如何保证可靠数据传输:本真是把TCP那套搬到应用层上实现的
- 增加SEQ和ACK及重传机制
- 增加流量控制和拥塞控制
- 增加差错校验机制
2.1.2. TCP和UDP的头部格式
UDP:
16bit源端口号 + 16bit目的端口号 + 16bit包长度 + 16bit校验和 + 数据
TCP:
16bit源端口号 + 16bit目的端口号 + 32bit seq number + 32bit ack number +
4bit TCP首部长度 + 6bit 保留位 + 6bit标志位 + 16bit 窗口大小window +
16bit 校验和 + 16bit 紧急数据指针(?) + 长度可变的选项 + 数据
TCP 至少20字节,因为有选项,长度可变(所以必须要有4bit标识TCP首部长度)
控制位:SYN ACK FIN RST
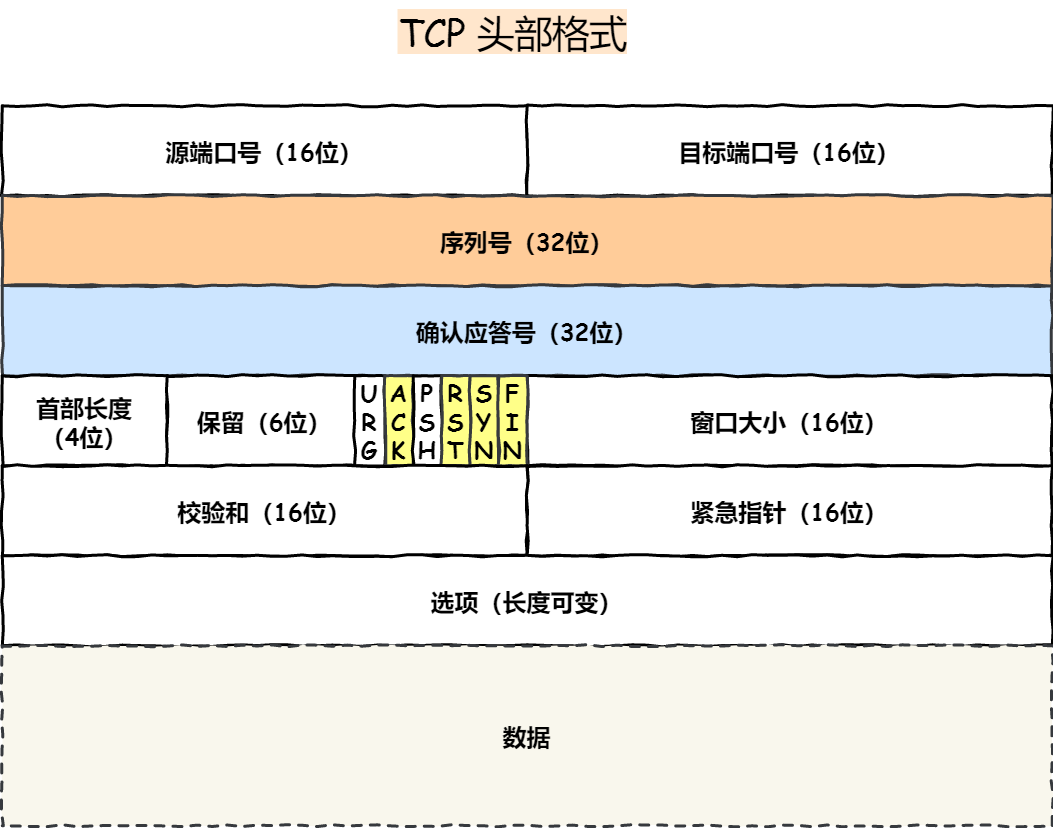
控制位
SYN=1表示建立连接请求
ACK=1表示确认号合法,为0的时候表示数据段不包含确认信息,确认号被忽略。
FIN=1表示用来释放连接请求,表明发送方已经没有数据发送了
RST=1表示出现异常需要立即中断连接,也表示拒绝非法数据和请求
其他不了解
TCP选项options有哪些,分别有什么作用?
kind = 2: 定义MSS大小
kind = 3: 扩大拥塞窗口
kind = 4, 5:sack机制
kind = 8: timestamp
kind = 34: fast open
blob:https://q1ht0wsrvr.feishu.cn/2a62ceee-c21d-4978-b2c6-ab996c1502c0
这部分最多包含40字节(TCP首部最多60字节)
选项第一个字段1字节 kind,有的TCP选项没有后面两个字段,仅包含1字节的kind字段
第二个字段length,1字节,
第三个字段info
TCP有了 checksum 还可能会造成数据错乱吗
有可能,因为 TCP CheckSum 是通过按照 16位进行处理的,之后给这是十六位进行不断循环加法,最后取反
所以如果同时有两位都出错那么就可能 checkSum 正确而数据错乱
2.2. 三次握手
2.2.1. 过程?
a. 客户端发送 SYN =1 SEQ NUM = x, 客户端进入SYN-SENT阶段
b. 服务端回复标志位为SYN = 1ACK = 1, SEQ NUM = y, ACK NUM = x + 1, 服务端进入SYN-RCVN阶段,并为这次连接分配资源
c. 客户端接收TCP报文以后,回复SEQ NUM = x + 1, ACK NUM = y + 1,随后客户端建立ESTABLISHED阶段,并为这次连接分配资源。server接收到之后也进入ESTABLISHED阶段。
ack num是根据别人发来的seq num + 1
seq num是自己的,是上次自己发送的sql num + 1
第二次握手传回了ACK,为什么还要传回SYN?
回传ACK表明收到了client的SYN请求
回传SYN则为了请求建立连接
2.2.2. 为什么三次握手?
为什么不能两次握手?
-
两次握手的做法:client发送syn = 1,server接收到并初始化资源,状态变成ESTABLISHED,接着发送ACK = 1,SYN = 1,客户端收到也变成ESTABLISHED状态。
-
三次握手的根本目的是为了防止旧的连接初始化造成资源浪费,情况如下:client发送了seq = 90,然后client重启了又发送seq = 100,server接受到seq = 90发送ACK 91,如果是两次握手此时已经初始化了连接资源。但是client期望收到ACK=101,却受到了ACK=91,所以发送RST中断连接,之前的连接资源就浪费了。
-
三次握手还可以同步双方初始序列号
什么时候可以两次握手?
半开连接,也就是两端已经建立了一次三次握手,但是由于异常原因一方中断,那么此时会进行两次握手
为什么不四次握手?
- 先考虑如何进行四次握手:client发syn,server发ack,server发syn,client发ack
- 不进行四次握手的原因:其中第二、三步是可以合并的
2.2.3. 第一、二、三次握手报文丢失了怎么办?
第一次握手报文丢失了会怎么办?
<1> 如果第一次握手的报文丢失了,client会触发重传机制,具体来说,其会在1s后重传,最大重试次数为5次。且每一次重试的时间为1s, 2s, 4s, 8s, 16s, 32s。
<2> 重传的seq是不变的
第二次握手报文丢失了会怎么办?
<1> client会重传第一次握手的报文,因为没有收到SYN-ACK请求
<2> server会重传第二次握手的报文,因为没有收到三次握手的ACK请求
第三次握手的报文丢失了会怎么样?
第三次握手报文丢失了,server会重传SYN-ACK。重传次数由内核文件决定。
2.2.4. 什么是SYN攻击?
伪造IP发送SYN报文,server加入到半连接队列SYN队列。但是收不到ACK响应,无法从SYN队列移到accept队列,导致SYN队列满了。
解决办法:
- 增大半连接队列
- 可以绕开SYN队列直接用cookie去跟client校验,然后直接加入到Accept队列
- 减少SYN+ACK重传次数(server大量处于SYN_RECV,接收不到ACK会重传SYN+ACK)
2.2.5. TCP建立后把网线切掉会发生什么?(客户端主机突然故障了)
- TCP有Keep alive保活机制,server定时发送小数据包,client的系统检测到连接中断则发送RST(如果宕机则没有响应,server重试几次后也会中断连接)。
- 接收方收到RST信号,直接断开连接,不会执行四次挥手
2.2.6. TCP建立后服务端进程崩溃了会发生什么?
内核会发FIN报文
2.3. 四次挥手
2.3.1. 过程?
- client向server发送FIN = 1,变为FIN_WAIT1,停止发送数据,可以接收数据
- server回复ACK = 1,进入CLOSE-WAIT状态,client收到ACK变为FIN_WAIT2
- server回复FIN = 1,进入LAST ACK
- client收到FIN,变为TIME_WAIT,2MSL后变为CLOSE,发送ACK。server收到ACK变为CLOSE
注意:
- 一旦TCP的一方发送了FIN以后就不能发送数据了。四次挥手的前两步和后两不是对称的
- 关闭连接的一方必须等待对方ACK才能确认关闭
2.3.2. 为什么不能三次挥手?
-
三次挥手应该怎么做?根据TCP三次握手可以设想是第二步和第三步合并,但是其实server接受到FIN报文后无法立即关闭socket,要先回复一个ACK,等把当前所有的(缓存中的)数据都处理完才发送FIN报文,所以要四次挥手。
-
有一种情况可以三次挥手:上游已经把所有数据处理完了
2.3.3. 为什么TCP的第二次挥手之后客户端进入FIN_WAIT_2状态?
FIN_WAIT_2表示server端已经收到了client的FIN请求,此时client可以正常关闭
如果这个时候网络突然断掉,导致client不能收到来自server的ACK,其就会在FIN_WAIT_2状态的定时器超时的时候主动释放该连接,进入CLOSE状态。
2.3.4. 第一、二、三、四次挥手失败了怎么办?
握手:第一次client,第二次client和server,第三次是server
挥手:第一次或者是第二次丢失,则client重发FIN / 如果是第三次或者是第四次丢失,则server重发FIN
2.4. TIME_WAIT状态
2.4.1. 大量TIME_WAIT的原因
TIME_WAIT是收到第二个FIN之后,CLOSED_WAIT是收到第一个FIN之后
TIME_WAIT是主动方 CLOSED_WAIT被动方
原因:
- 短连接:每一次连接都要三次握手四次挥手,server端出现大量的TIME_WAIT状态(都是server端主动断开连接)
- 长连接超时:建立连接后长时间不发送请求,长连接占用资源。HTTP使用了长连接,那么nginx会设置一个定时器(60s),在60s之内没有发送任何请求的时候就会发生超时,导致server端出现大量的TIME_WAIT状态
- HTTP 长连接的请求数量达到上限。如果达到这个参数设置的最大值时,则 nginx 会主动关闭这个长连接,那么此时服务端上就会出现 TIME_WAIT 状态的连接。
大量TIME_WAIT的危害?
占用文件描述符fd等系统资源,也占用端口资源(就是占用资源嘛)
如何优化大量TIME_WAIT状态?
- 开启长连接 connection:keep_alive机制
- 降低TIME_WAIT状态时间
- 调整nginx参数,如上面原因中的参数
- TIME_WAIT复用?
2.4.2. TIME_WAIT为什么要等待2MSL
- 防止旧连接的数据包:经过2MSL,可以保证新连接不会接受到旧连接的包
- 保证连接正常关闭:变为TIME_WAIT之后会发ACK,丢失的话server还会补发FIN。如果立马close,server无法确定是否client正常关闭(给个补发接收时间)。
2.5. CLOSED_WAIT状态
2.5.1. 什么时候会出现大量的CLOSED_WAIT状态?
CLOSED_WAIT状态之后调用close()函数,出现大量的CLOSED_WAIT状态说明没有调用close()
2.5.2. 出现大量的CLOSED_WAIT有什么影响?
与大量TIME_WAIT一样吧,fd增加,新建连接失败
2.6. Socket编程
2.6.1. Socket的API
server:
- 首先调用socket()系统调用进行初始化
- 使用bind绑定端口
- 使用listen开始监听(listen的函数原型为listen(socket_fd, backlog),其中的backlog是Accept队列
- 使用accept接受请求(阻塞接受SYN,接受到后发送SYN+ACK)
- 使用recv接受请求
- 使用send发送请求
- 最后调用close关闭socket连接
client:
-
首先调用socket()系统调用进行初始化
-
使用connect连接目标服务器(发SYN请求)
-
使用send写数据
-
使用recv读数据
-
最后调用close关闭socket连接
2.6.2. 体现在三次握手上?
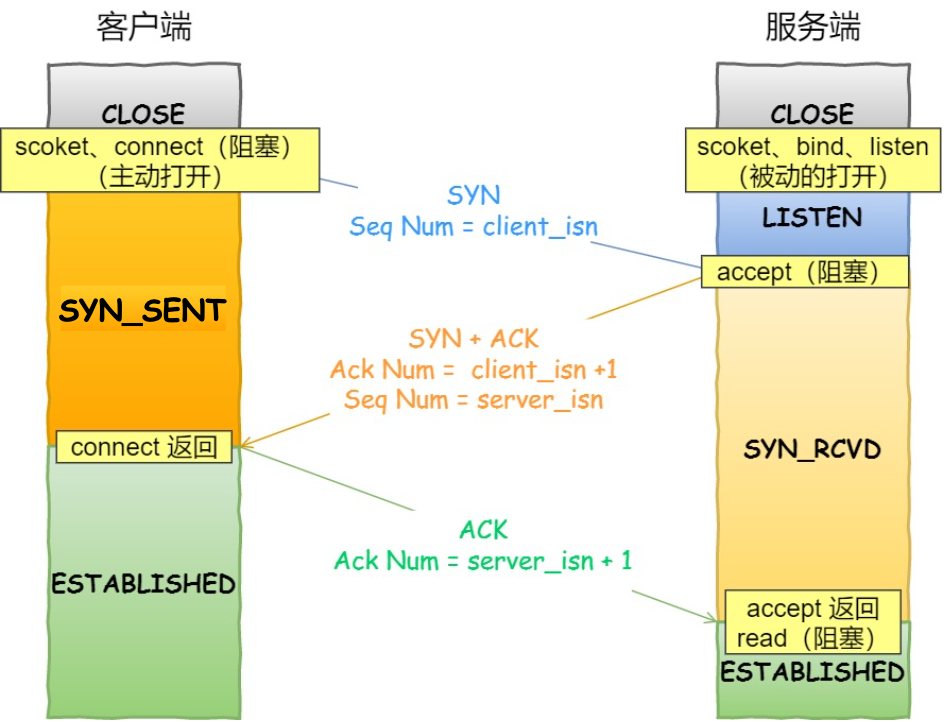
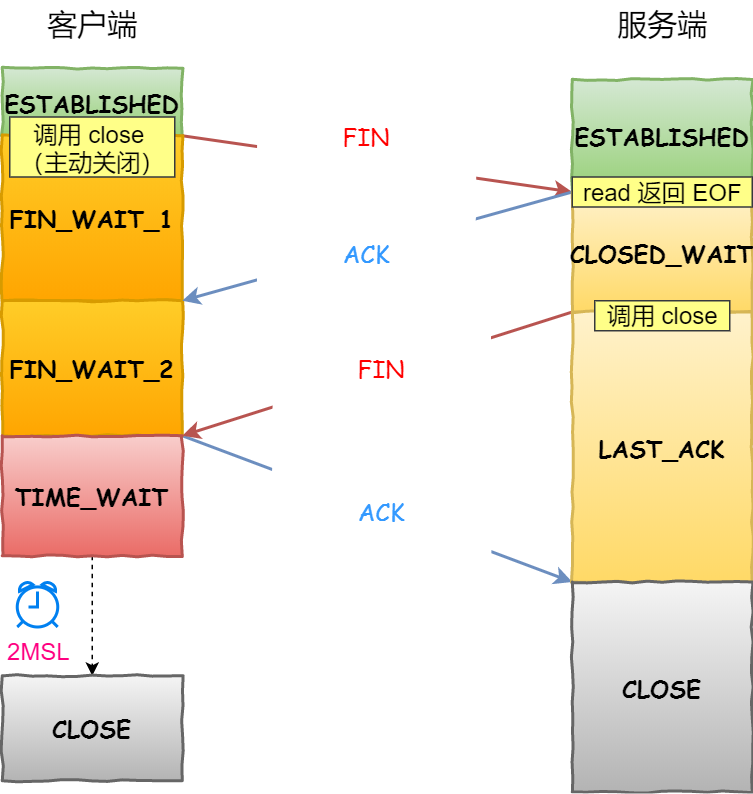
2.7. 如何保证可靠性的?
2.7.1. 重传机制
超时重传
数据包丢失,ACK丢失
快速重传
三个ACK
SACK
这种方式需要在 TCP 头部「选项」字段里加一个 SACK 的东西,它可以将已收到的数据的信息发送给「发送方」,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。
D-SACK
接收方发送的TCP带上重复接受到的数据,可以判断是ACK丢包引起的还是网络延迟引起的:
- 如果有两个ACK且第二个ACK带有重复说明是网络延迟
- 如果只有一个ACK且带有重复说明是ACK丢包
2.7.2. 滑动窗口
三段斧:a. 已发送并接收 b. 已发送但未接收 c. 未发送但在窗口内 d. 未发送且未在窗口内
b + c 构成窗口
累计确认(连续ARQ协议)
发送窗口大小 = min(流量窗口 + 拥塞窗口)
2.7.3. 流量控制
如果发送方发送的太快,应用程序来不及使用, 就会把缓冲区挤满, TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。
2.7.4. 拥塞控制
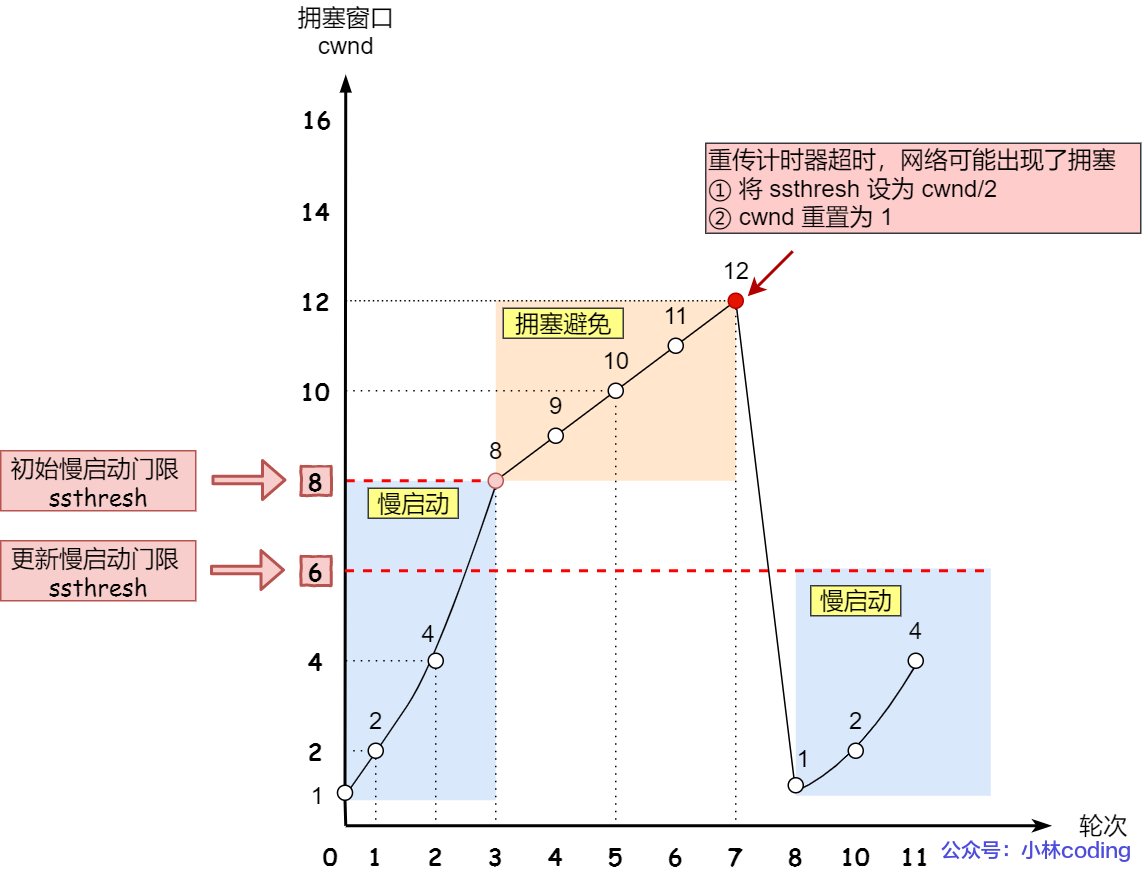
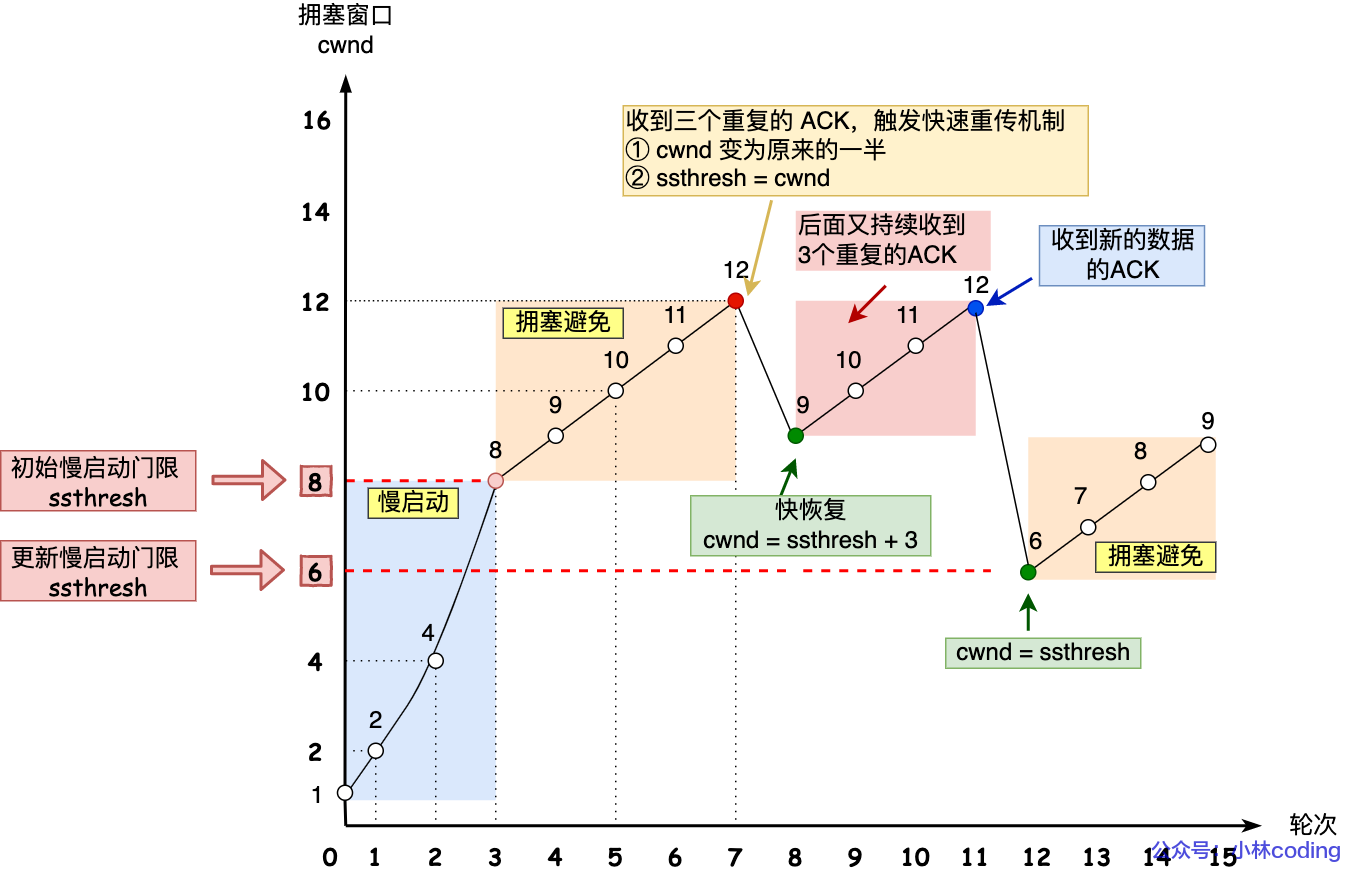
2.8. MSS&MTU&MSL
2.8.1. MSL
MSL是指报文在网络中最长的存在时间
Linux中默认的是2MSL, 60秒。
原因是因为,Linux认为第四次挥手发送的ACK如果没有被收到,此时server会发送一个FIN,如果server没有收到ACK,那么会重发FIN。这样一来一回的时间是2MSL。如果到了这个时间依然没有收到FIN,则关闭就可以
在Linux里面是固定值60秒
2.8.2. MSS
MTU:最大传输单元,由硬件规定,如以太网的MTU为1500字节。
MSS:最大分节大小,为TCP数据包每次传输的最大数据分段大小,一般由发送端向对端TCP通知对端在每个分节中能发送的最大TCP数据。
MSS值为MTU值减去IPv4 Header(20 Byte)和TCP header(20 Byte)得到。
2.8.3. MTU
2.9. TCP中的粘包问题
TCP粘包就是指发送方发送的若干包数据到达接收方时粘成了一包,从接收缓冲区来看,后一包数据的头紧接着前一包数据的尾。
原因:
- 发送方:Nagle算法,收集多个小分组一起发送,导致粘包
- 接收方:上层应用处理得慢,缓冲区多个包收尾连在一起
如何:
- 发送方:关闭Nagle算法
- 接收方:应用层处理粘包
- Http 1.1中可以获取长度
- 数据定义前后缀分隔符
UDP不存在粘包问题?
UDP面向消息,一次传输一整个消息。不会有不同消息黏在一起的情况。
2.10. DNS和CDN
2.10.1. DNS的功能
基于UDP
-
域名转IP:可以把DNS服务器理解为KV数据库
-
根域名服务器,顶级域名服务器,权限域名服务器,本地域名服务器
2.10.2. CDN
内容分发网络
- 静态资源缓存:CDN将网站的静态资源缓存在离用户比较近的节点上,用户请求的时候会从近的节点去获取资源
- 负载均衡:CDN根据地理位置,选择近的服务器去访问
- 动态内容优化:在传递动态数据时,可以对数据进行压缩、加速和缓存处理,减轻源服务器负载。
- CDN:可以提供一些安全防护
3. IP
3.1. IP数据包的格式
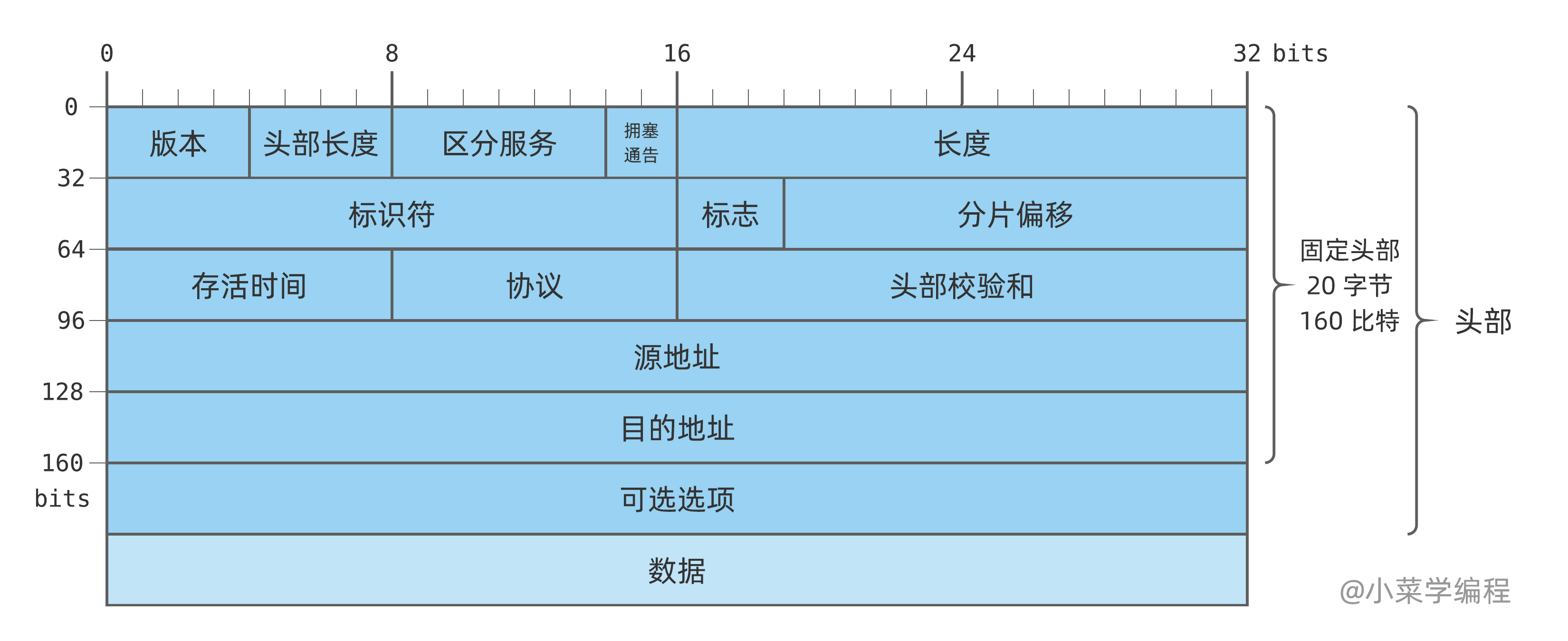
a. 4bit 版本:IPV4即是4
b. 4bit 首部长度:最大长度为60字节
c. 8bit 区分服务类型:一般不用
d. 16bit 总长度:即IP总包长度
e. 16bit 标识:
f. 标志位
1. 第0位,保留,必须为0
1. 第1位,禁止分片,该位为0才允许分片
1. 第2位,更多分片,该位为1表示后面还有分片,为0表示已经是最后一个分片g. TTL生存时间
h. 8位协议:上层协议报文 TCP /UDP /ICMP等
i. 16位首部校验和:只是对IP头部查错
j. 源地址:32位
k. 目的地址:32位
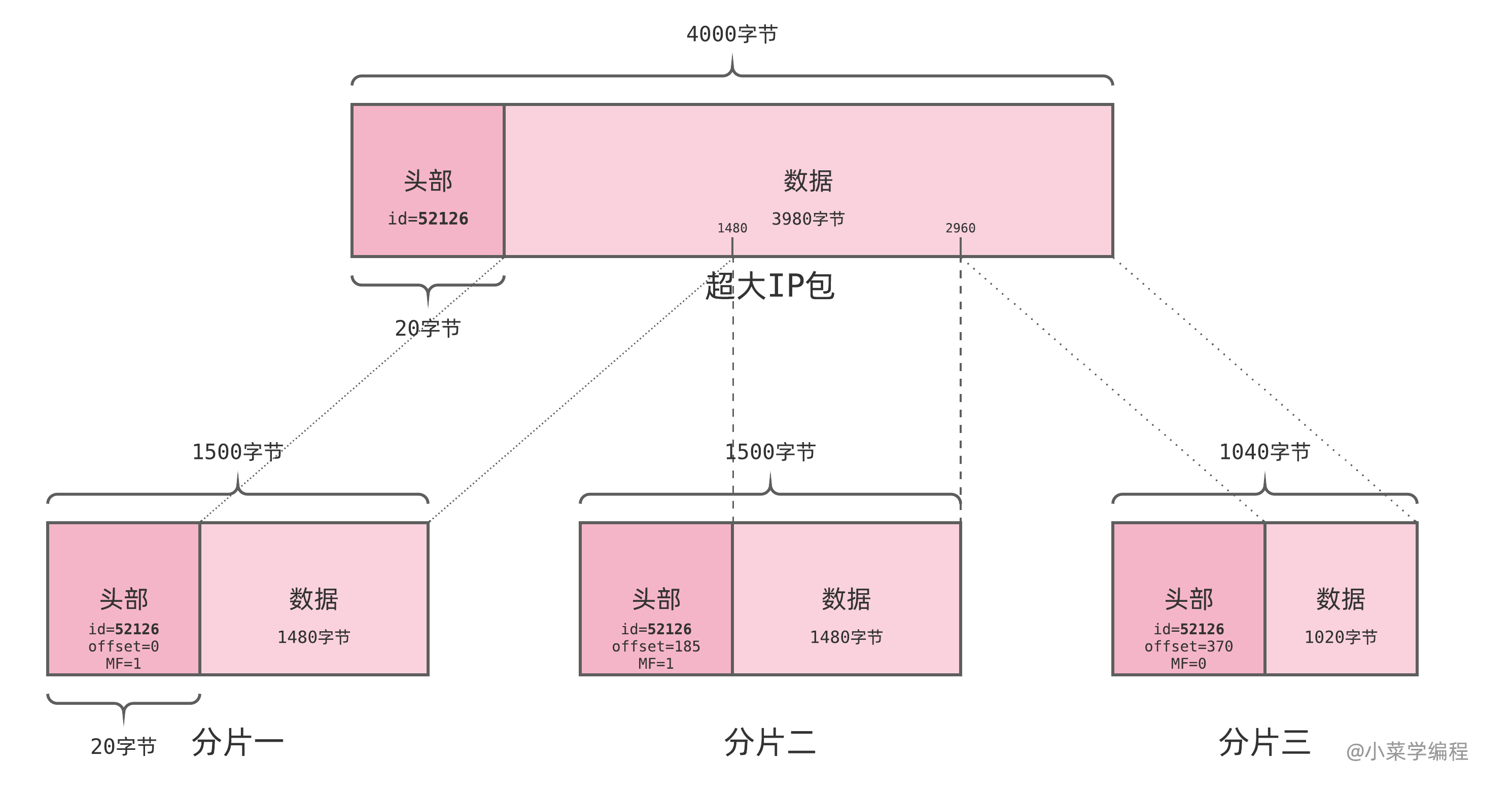
3.2. IP地址的结构
前面n位是网络号,后面32-n位是主机号
3.2.1. C 类地址哪些是保留地址
192.168.0.0~192.168.255.255 作为私有地址,不能再广域网中使用
3.2.2. 三级结构?子网掩码
网络号 + 子网号 + 主机号 子网号是解决避免浪费
3.3. 使用子网掩码转发IP分组
a. 在划分子网的情况下,从IP地址不能唯一地得出网络地址来,这是因为网络地址取决于那个网络所采用的子网掩码。但数据报的首部并没有提供子网掩码的信息。
b. 因为分组转发的算法也必须相应的改动
3.4. CIDR
不再有地址分类概念。表示形式 a.b.c.d/x,其中 /x 表示前 x 位属于网络号, x 的范围是 0 ~ 32,这就使得 IP 地址更加具有灵活性。
比如 10.100.122.2/24
3.5. IP协议相关的技术
3.5.1. DNS
见前面
3.5.2. ARP
发送广播包,带上目的IP,收到的节点递交到网络层看是不是自己的ip,是的话就返回回应 + MAC地址
3.5.3. DHCP
- 客户端广播发送DHCP discover报文
- DHCP服务器收到DHCP discover报文,发送一个DHCP offer报文,带上提供的IP信息和DHCP服务器地址
- 客户端选择收到的第一个DHCP offer报文,然后发送DHCP request,带上DHCP服务器地址,接受租约的IP和租约时间
- DHCP服务器发送DHCP ACK,带上DHCP服务器地址和确认IP信息
3.5.4. NAT
缓解了 IPv4 地址耗尽的问题。
路由器上有一个路由转换表,内网多个不同私有ip会被转换为同一个公有ip
缺陷
-
外部无法主动与 NAT 内部服务器建立连接,因为 NAPT 转换表没有转换记录。
-
转换表的生成与转换操作都会产生性能开销。
-
通信过程中,如果 NAT 路由器重启了,所有的 TCP 连接都将被重置。
解决
- 换成IPV6
- NAT穿透技术:说人话,就是客户端主动从 NAT 设备获取公有 IP 地址,然后自己建立端口映射条目,然后用这个条目对外通信,就不需要 NAT 设备来进行转换了。
3.5.5. ICMP
负责网际通信中 控制信息 和 差错信息 的传送。
3.5.6. IGMP
组播地址
3.6. IPV6如何解决IP枯竭的问题
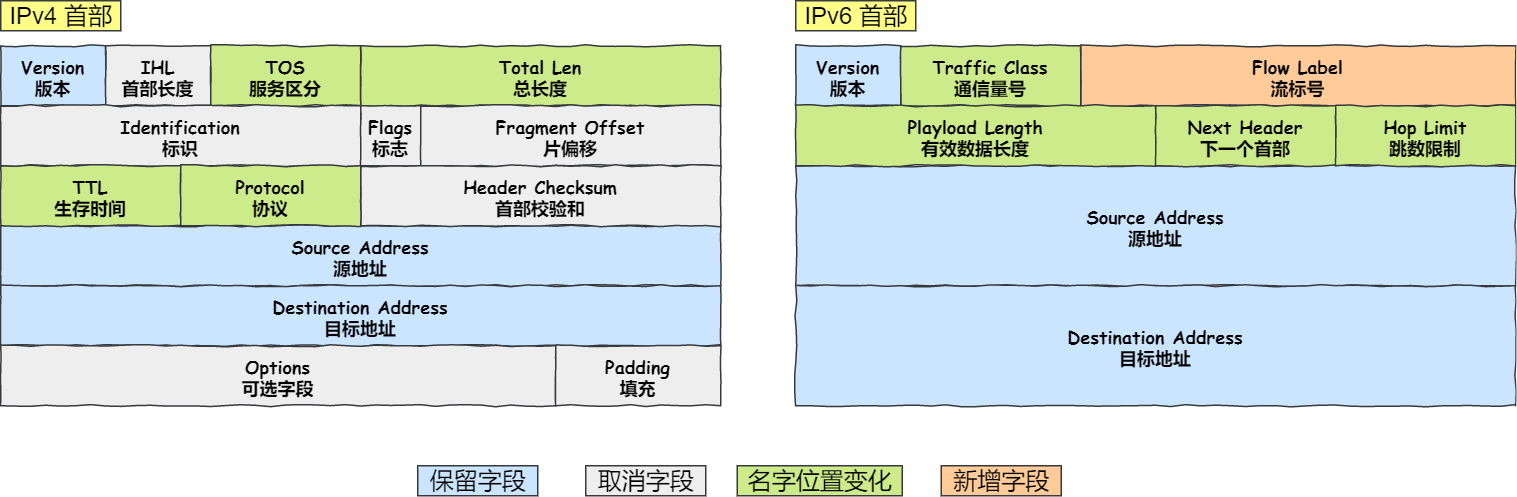
- IP分组的都没了,IPV6不分组了,影响效率
- 不校验了,跟传输层重了
- 可选字段去掉,放在下一个首部了
全0全1
主机号全 0 表示主机地址(初始地址)
主机号全 1 表示广播地址
- 网络号和主机号都为全 0 的地址表示整个 IP 地址空间中的地址 0.0.0.0,通常称为 “通配地址” 或 “本地地址”。
- 网络号全 0,主机号全 1 的地址是子网广播地址,表示该子网内的所有主机都会接收到该广播消息。
- 网络号全 1,主机号全 0 的地址是 IP 地址空间中的 “限定广播地址”,表示发送给该地址的数据包会在所有网络中传播。
- 网络号和主机号都为全 1 的地址表示本网络地址或者一个广播地址。
记忆:全为1代表就是ANY的意思
网络号全为1,主机号全为0则是任意网络。
主机号全为1,网络号全为0则是本网络所有主机。
4. 网络安全
4.1. SQL注入
SQL注入攻击是指当使用字符串拼接的方式生成SQL时,容易出现将恶意代码拼接入SQL的情况,例如select * from user where password = ”***” ‘or ‘1’=‘1’
预防方式
- 尽可能不使用SQL拼接的方式生成SQL
- 尽量使用预编译好的Statement,而不是自定义SQL
4.2. DDoS攻击/洪范攻击
DDOS:构造大量的请求,在收到server的ACK之后等待,不发送三次握手的请求,导致server创建了大量的半连接队列(即SYN攻击)
解决:
- 缩短超时时间
- 增大最大半连接数
- SYN Cookie绕过半连接SYN队列
4.3. XSS攻击
XSS 攻击通常是我们给用户定义了一个输入框,然后用户通过输入框输入了一些代码一样的数据,比如 SQL 语句,再比如一些 JS 语句之类的,当前端或者被拉到后端执行的时候,就会有潜在的问题,比如 SQL 注入、看不到前端的代码等等
4.4. 中间人攻击
在服务端给客户端发送公钥的过程中,中间人自己生成公钥和私钥代替服务端发送的公钥和私钥
防范:采用 CA 认证
4.5. CSRF
5. IO多路复用
前置知识:
socket作为fd的存在,其inode指向内核中的socket结构,socket结构维护两个队列SYN 队列和accept队列,每个队列都是一个个struct sk_buff,用链表组织起来。
不同协议层次都是用sk_buff->data通过调整指针头完成加头拆头
5.1. 多进程版本
accept()之后fork一个进程,因为struct task的files也会拷贝,所以指向的socket不变,依然可以对那些客户端连接资源(accept返回的fd,即连接的客户端socket)进行处理。
缺点
很明显,创建进程开销大,可以改成线程
5.2. 多线程版本
将进程改为线程,然后用线程池维护
缺点
并发度还是不够高
5.3. IO多路复用
概念:一个进程维护多个客户端socket连接资源
5.4. select/poll
将已连接的socket拷贝到内核,内核负责监听socket集合中有没有读请求到来的socket,检查的方法就是遍历,将可读或者可写的拷贝到用户空间,用户去做处理。
缺点:
-
两次内核和用户之间的拷贝,两次O(n)遍历
-
select用的1024长度的数组,poll用的动态数组
5.5. epoll
- select是相当于将accept()得到客户端连接的socket先拷贝到内核,而epoll直接对监听的socket在内核中维护一棵红黑树
- epoll使用事件驱动,当有客户端连接有socket独写事件的时候就通过回调函数直接将这个加入到就绪事件列表,而select需要轮询
ET边缘触发
读事件只通知一次
LT水平触发
有读事件就一直通知
5.1. Reactor 和 Proactor
5.1.1. 单Reactor单进程/线程
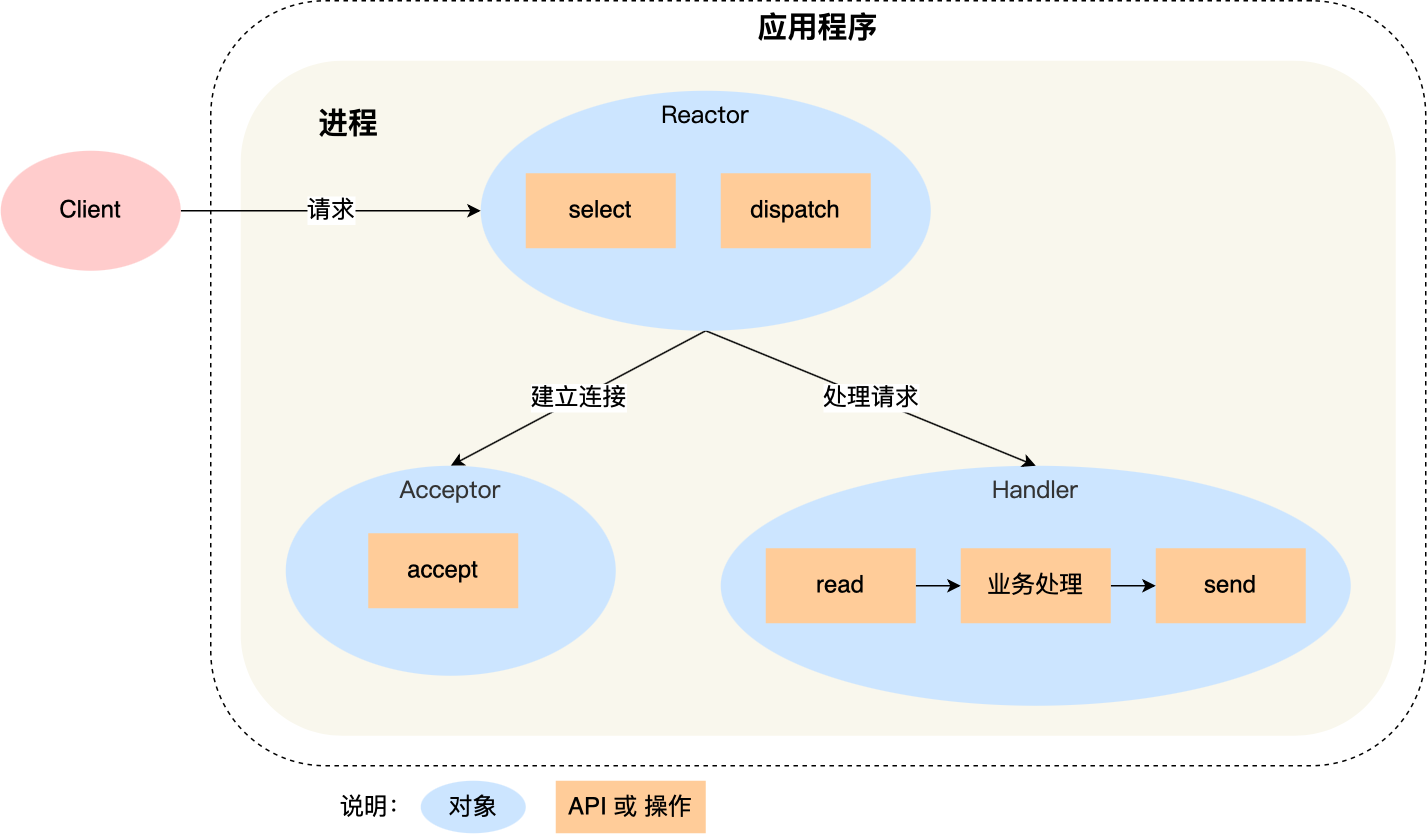
- Reactor通过select多路复用接口监听事件,dispatch用来分发事件,如果是创建连接事件则交给Acceptor处理,如果是read请求则交给Handler处理
- 连接事件交给Acceptor处理,得到一个socket客户端连接对象,交给Handler处理
- Handler对socket客户端发来的数据依次进行read->业务处理->send
缺点:
- 只有一个进程,无法充分利用多核CPU的性能
- 业务耗时比较长,影响别的处理
5.1.2. 单Reactor多进程/线程
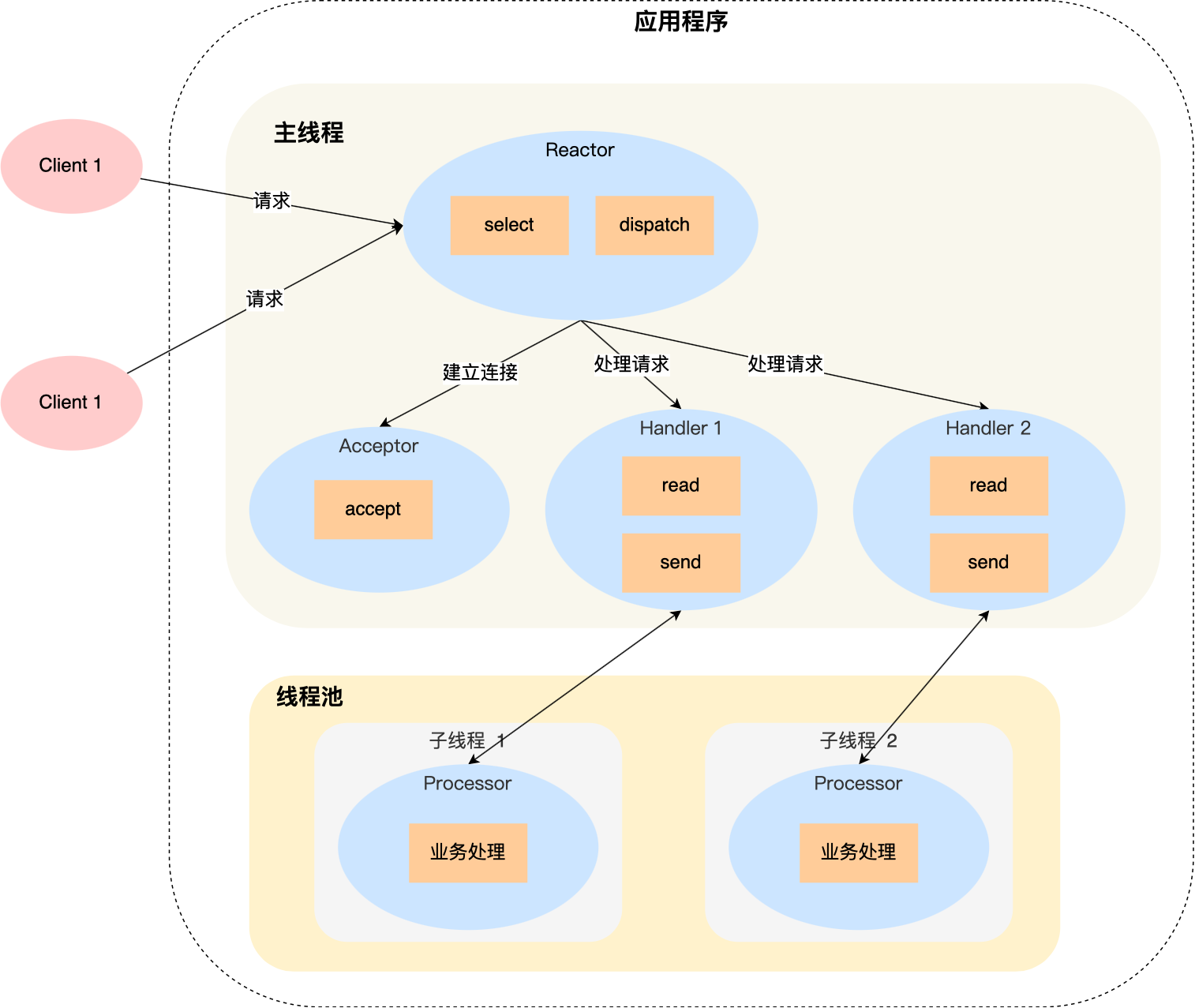
相比于单Reactor单进程/线程,处理业务是单独的线程池
缺点:
因为一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
5.1.3. 多Reactor多进程/线程
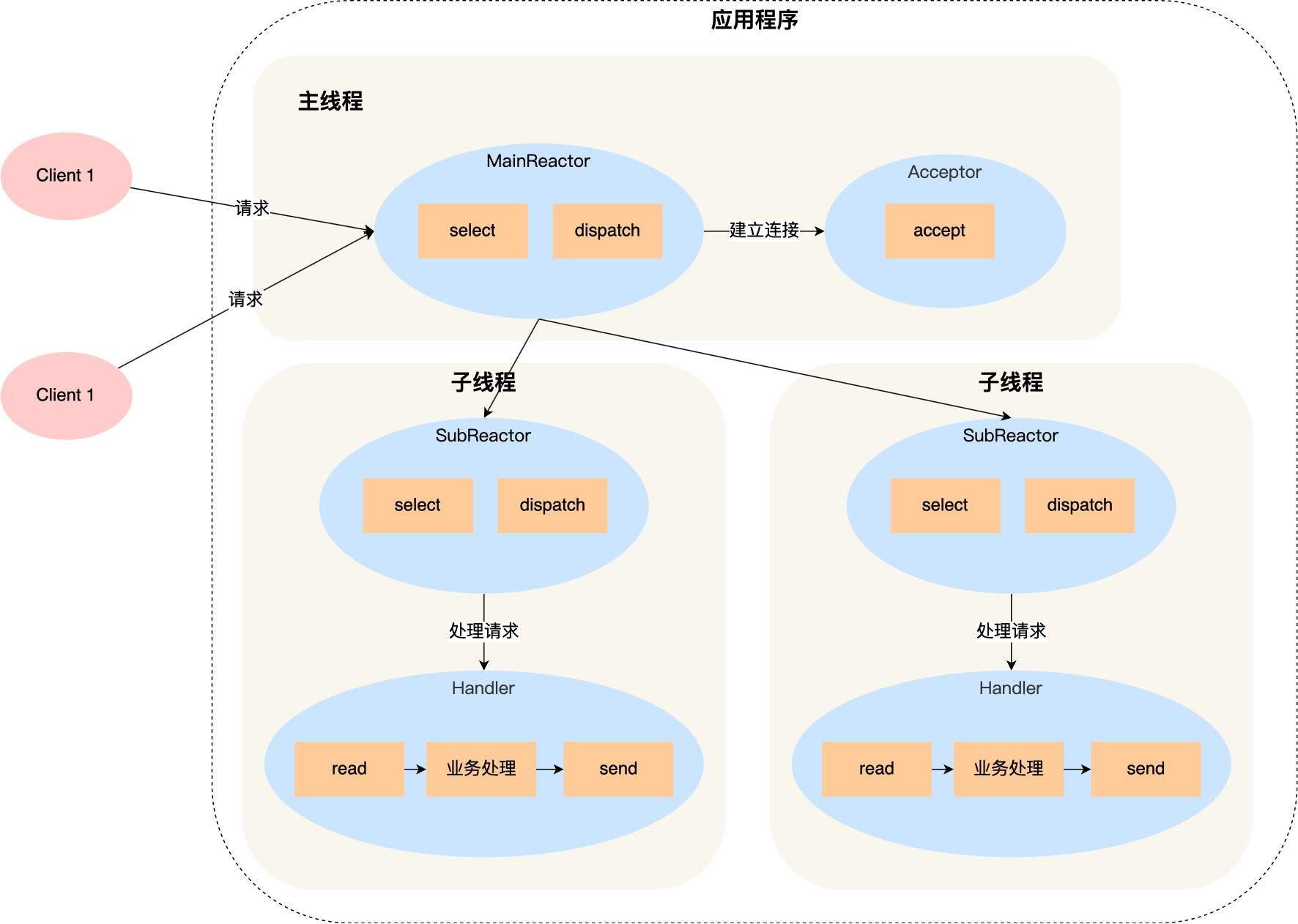
- 主Reactor只负责监听连接事件,连接事件交给Acceptor处理,得到的连接对象交给从reactor
- 从reactor也用select监听socket事件,监听到则交给Handler处理
开源:Netty和Memcache
5.1.4. Proactor
前置知识:
虽然epoll实现了有读事件到来异步返回,但是处理的时候还是使用的阻塞的read()调用
真正的异步io是说内核拷贝数据到用户空间完成之后异步通知用户程序,而不用让用户程序等待aio_read()
流程详见:9.3 高性能网络模式:Reactor 和 Proactor | 小林coding (xiaolincoding.com)
6. 杂题
6.1. URI和URL的区别?
- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。URL是一种具体的URI,提供路径信息
6.2. PING发生了什么?
发送方主机封装ICMP数据包,类型是8(回送请求消息),带上序号。带上IP头,MAC头,发送出去
主机B收到,检查MAC,IP匹配,构造一个ICMP回送响应消息,类型0,序号相同。
发送方主机接受到ICMP回送响应消息则证明可以ping通,否则。
6.3. 访问www.google.com发生了什么?
从协议栈的角度来看:
- DHCP: 向DHCP服务器发送请求获取本机IP地址
- ARP: 向网关路由器发送ARP请求获取目的网关的MAC地址
- DNS: 获取google.com对应的IP地址
- 建立TCP连接,三次握手
- 发送HTTP请求,获取返回的结果,解析DOM树
- 四次挥手关闭TCP连接
复杂版见🌟Network面试题 - 飞书云文档 (feishu.cn)